算法刷题
备战算法国赛ing
Day 1 背包问题
01背包问题
有一个箱子容量为 V,同时有 n 个物品,每个物品有一个体积。
现在从 n 个物品中,任取若干个装入箱内(也可以不取),使箱子的剩余空间最小。输出这个最小值。
DP核心:找变量之间的状态转移方程
代码:
def knapsack(weights, capacity):
n = len(weights)
dp = [0] * (capacity + 1)
for i in range(n):
for j in range(capacity, weights[i] - 1, -1):
dp[j] = max(dp[j], dp[j - weights[i]] + weights[i]) # 修正状态转移方程
return capacity - dp[capacity] # 返回最小剩余空间
if __name__ == '__main__':
V = int(input())
n = int(input())
vlist = []
for i in range(n):
vlist.append(int(input()))
print(knapsack(vlist, V))
双重循环这段代码是解决0-1背包问题的核心部分,它的作用是通过动态规划逐步填充一个一维数组 dp,以找到在给定容量下能够装入的最大体积。以下是对这段代码的详细解释:
代码结构
for i in range(n): # 遍历所有物品
for j in range(capacity, weights[i] - 1, -1): # 从大到小遍历背包容量
dp[j] = max(dp[j], dp[j - weights[i]] + weights[i]) # 状态转移方程
1. 外层循环:遍历物品
for i in range(n):
- 这个循环的作用是逐个考虑每一个物品。
n是物品的总数,i是当前考虑的物品的索引。- 每次循环处理一个物品,决定是否将其加入背包。
2. 内层循环:遍历背包容量
for j in range(capacity, weights[i] - 1, -1):
- 这个循环的作用是考虑当前物品是否能加入到不同容量的背包中。
j表示当前背包的容量,从capacity(背包的最大容量)开始,逐步减少到weights[i]。- 为什么从大到小遍历?
- 如果从大到小遍历,每次更新
dp[j]时,dp[j - weights[i]]是基于之前状态的值(即未考虑当前物品i的状态)。这样可以避免重复使用同一个物品。 - 如果从小到大遍历,
dp[j - weights[i]]可能已经被更新过,这会导致同一个物品被多次使用,从而变成完全背包问题。
- 如果从大到小遍历,每次更新
3. 状态转移方程
dp[j] = max(dp[j], dp[j - weights[i]] + weights[i])
这是动态规划的核心部分,用于更新
dp[j]的值。dp[j]表示在背包容量为j的情况下,能够装入的最大体积。状态转移方程的含义是:
- 如果不选择当前物品
i,则背包容量为j时的最大体积仍然是dp[j]。 - 如果选择当前物品
i,则背包容量为j时的最大体积是dp[j - weights[i]] + weights[i],即在容量为j - weights[i]的情况下加上当前物品的体积。
- 如果不选择当前物品
最终,
dp[j]的值是两种情况中的最大值:dp[j] = max(dp[j], dp[j - weights[i]] + weights[i])
4. 代码的执行过程
假设背包容量为 V,物品体积为 [w1, w2, ..., wn],以下是代码的执行过程:
- 初始化
dp数组,dp[0] = 0(容量为0时,最大体积为0),其余位置初始化为0。 - 遍历每个物品
i:- 对于每个物品,从大到小遍历背包容量
j。 - 对于每个容量
j,如果当前物品i的体积weights[i]小于等于j,则考虑是否将物品i放入背包。 - 更新
dp[j]为两种情况的最大值:- 不放入物品
i:dp[j]保持不变。 - 放入物品
i:dp[j] = dp[j - weights[i]] + weights[i]。
- 不放入物品
- 对于每个物品,从大到小遍历背包容量
- 最终,
dp[capacity]表示在背包容量为capacity的情况下,能够装入的最大体积。
5. 输出结果
最终结果是 capacity - dp[capacity],表示背包的最小剩余空间。
示例
假设背包容量为 V = 10,物品体积为 [3, 4, 5],以下是代码的执行过程:
- 初始化
dp = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]。 - 遍历第一个物品(体积为3):
- 更新
dp[3]到dp[10]:dp[3] = max(dp[3], dp[0] + 3) = 3dp[4] = max(dp[4], dp[1] + 3) = 3- ...
dp[10] = max(dp[10], dp[7] + 3) = 3
- 更新
- 遍历第二个物品(体积为4):
- 更新
dp[4]到dp[10]:dp[4] = max(dp[4], dp[0] + 4) = 4dp[7] = max(dp[7], dp[3] + 4) = 7- ...
- 更新
- 遍历第三个物品(体积为5):
- 更新
dp[5]到dp[10]:dp[5] = max(dp[5], dp[0] + 5) = 5dp[10] = max(dp[10], dp[5] + 5) = 10
- 更新
- 最终,
dp = [0, 0, 0, 3, 4, 5, 3, 7, 5, 8, 10]。 - 输出结果:
10 - dp[10] = 0。
通过这段代码,我们能够动态地计算出在给定容量下能够装入的最大体积,从而求出最小剩余空间。
01背包问题(加上价值权重)
辰辰是个天资聪颖的孩子,他的梦想是成为世界上最伟大的医师。为此,他想拜附近最有威望的医师为师。医师为了判断他的资质,给他出了一个难题。医师把他带到一个到处都是草药的山洞里对他说:“孩子,这个山洞里有一些不同的草药,采每一株都需要一些时间,每一株也有它自身的价值。我会给你一段时间,在这段时间里,你可以采到一些草药。如果你是一个聪明的孩子,你应该可以让采到的草药的总价值最大。” 如果你是辰辰,你能完成这个任务吗?
具体看代码注释:
def knapsack(value, weight, capacity):
n = len(value)
dp = [[0] * (capacity + 1) for _ in range(n + 1)] # 实际长度为容量加1(要考量容量为0的情况)
# 0行和0列一定为0
for i in range(1, n + 1): # 要添加的物品价值为i时(按行遍历)
for j in range(1, capacity + 1): # 遍历每一种容量的背包 j为容量
if weight[i - 1] <= j:
# 当容量足够加入该物品时,进行对比
"""如果没有这个物品介入时,同为j容量的背包能装得的物品最大价值dp[i - 1][j]
以及如果选择装入这个物品(value[i - 1])与剩下容量能装入的最大价值dp[i - 1][j - weight[i - 1]]的和
在两者之间比较最大值取就行
"""
dp[i][j] = max(value[i - 1] + dp[i - 1][j - weight[i - 1]], dp[i - 1][j])
else: # 当要添加的物品加不进背包时候,最优解就是同容量背包不加这个物品的时候的最优解
dp[i][j] = dp[i - 1][j]
# 最后一行的capacity列的值就是所求的最优解, 即容量为capacity的背包能装入的物品最大价值
return dp[n][capacity]
if __name__ == '__main__':
T, M = map(int, input().split(' '))
# T就是背包容量
tlist = [] # 存每个物品的耗时(即物品需要的背包容量)
mlist = [] # 存每个物品价值
for i in range(M):
t, m = map(int, input().split(' '))
tlist.append(t)
mlist.append(m)
print(knapsack(mlist, tlist, T))
Day2 快速幂算法
快速幂算法(也称为“快速指数运算”或“快速幂取模”)是一种高效的算法,用于计算 a**bmodm,即计算 a 的 b 次幂对 m 取模的结果。该算法的核心思想是通过将指数 b 分解为二进制形式,从而将问题分解为若干个较小的幂次运算,大大减少了计算量。快速幂算法的核心是每个数的n次方,则分解为数的形式,如2的7次方可以分解为2的1次方乘以2的2次方乘以2的四次方.而对应的二进制中为1位是有规律的。
1. 快速幂算法的基本原理
快速幂算法利用了指数的二进制表示和幂的性质。具体来说,任何整数 b 都可以表示为二进制形式,例如:
b=b**k⋅2k+b**k−1⋅2k−1+⋯+b1⋅21+b0⋅20
其中 b**i 是二进制位(0 或 1)。因此:
a**b=abk⋅2k+b**k−1⋅2k−1+⋯+b1⋅21+b0⋅20
根据幂的性质,可以进一步分解为:
a**b=(a2k)b**k⋅(a2k−1)b**k−1⋅⋯⋅(a21)b1⋅(a20)b0
由于 b**i 只能是 0 或 1,因此 a2i 只有在 b**i=1 时才会被乘入最终结果。
2. 快速幂算法的实现步骤
快速幂算法的核心是通过循环逐步计算 a2i,并根据 b**i 的值决定是否将其乘入最终结果。具体步骤如下:
输入:
- a:基数
- b:指数
- m:模数
输出:
- a**b mod m
算法步骤:
- 初始化结果为 1,即 result=1。
- 将基数 a 对模数 m 取模,即 a=amodm。
- 遍历指数 b 的每一位(从最低位到最高位):
- 如果当前位为 1(即 b**i=1),则将当前的 a2i 乘入结果,并对 m 取模。
- 将基数 a 平方,并对 m 取模,即 a=(a×a)modm。
- 将指数 b 右移一位(相当于除以 2)。
- 当指数 b 为 0 时,循环结束,返回结果。
3. Python 实现
以下是快速幂算法的 Python 实现:
def Binexp(a,n):
r = 1
while n > 0:
if n % 2 == 1 : #如果n的二进制最后一位是1,则乘入r
r *= a
a *= a #a更新到下一个为偶次方的值上
n //= 2 #n //= 2的含义就是将n的二进制的最后一位消灭掉
return r
当然,可以将其中的一些运算换成位运算,与运算
def Binexp(a, n):
r = 1
while n > 0:
if n & 1: #n & 1表示n与1的二进制做位运算,只看最后一位是否相等,相等说明n的二进制最后一位是1
r *= a
a *= a
n >>= 1 # n 对2整除并向下取整等效于将n的二进制右移一位
return r
4. 快速幂算法的优势
- 时间复杂度:快速幂算法的时间复杂度为 O(logb),因为每次循环都将指数 b 减半。
- 空间复杂度:快速幂算法的空间复杂度为 O(1),因为它只需要常数级的额外空间。
- 适用场景:特别适用于大整数的幂运算和模运算,例如在密码学和数论问题中。
5. 取模
小蓝想要构造出一个长度为10000 的数字字符串,有以下要求:
- 小蓝不喜欢数字 0 ,所以数字字符串中不可以出现 0 ;
- 小蓝喜欢数字 3 和 7 ,所以数字字符串中必须要有 3 和 7 这两个数字。
请问满足题意的数字字符串有多少个?这个数字会很大,你只需要输出其对 109 + 7 取余后的结果。
原理:
在适当位置加入取模运算即可
a的n次方对m取模
代码:
def qumo(a, n, m):
a = a % m # 将基数 a 对模数 m 取模,减少后续计算中的数值大小
r = 1 # 初始化结果 r 为 1(因为任何数的 0 次幂都是 1)
while n > 0: # 当指数 n 大于 0 时继续循环
if n & 1 == 1: # 如果 n 的二进制最低位是 1
r = (r * a) % m # 将当前的 a 乘入结果 r,并对 m 取模
a = (a * a) % m # 将 a 平方,并对 m 取模
n >>= 1 # 将 n 右移一位(相当于 n = n // 2)
return r # 返回最终结果
按为了求解这个问题,我们需要计算满足以下条件的长度为10000的数字字符串的数量:
- 字符串中不能包含数字0。
- 字符串中必须包含数字3和7。
首先,我们计算不包含数字0的长度为10000的数字字符串的总数。由于每个位置可以是1到9中的任意一个数字,所以总共有 910000 个这样的字符串。
接下来,我们需要减去不包含数字3或不包含数字7的字符串数量。不包含数字3的字符串中,每个位置可以是1到9中除了3以外的8个数字,所以总共有 810000 个这样的字符串。同样,不包含数字7的字符串也有 810000 个。
但是,我们减去的太多了,因为那些既不包含数字3也不包含数字7的字符串被减去了两次。所以,我们需要加上既不包含数字3也不包含数字7的字符串数量。这样的字符串中,每个位置可以是1到9中除了3和7以外的7个数字,所以总共有 710000 个这样的字符串。
因此,满足条件的字符串数量为: 910000−2⋅810000+710000
由于这个数字非常大,我们需要对 109+7 取余。我们可以使用快速幂算法来计算 910000mod(109+7),810000mod(109+7),和 710000mod(109+7)
print((qumo(9, 10000,10**9+7)-2*qumo(8,10000,10**9+7)+qumo(7,10000,10**9+7))%(10**9+7))
6. 斐波那契的第i项
原理:
所以,只需要计算出矩阵的n次方就可以得到第n项的值
最重要的就是计算矩阵的n次方
import numpy as np
def fibonacci3(n):
A = np.array([[0, 1], [1, 1]], dtype=np.object_)
R = np.eye(A.shape[0], dtype=np.object_)
while n > 0:
if n & 1:
R = np.dot(R, A)
A = np.dot(A, A)
n >>= 1
return R[1,0]
A = np.array([[0, 1], [1, 1]], dtype=np.object_)创建一个矩阵A
R是初始化一个基于A的形状的0矩阵
返回的R[1,0]就是我们需要的值
6. 总结
快速幂算法是一种高效且实用的算法,通过将指数分解为二进制形式,利用幂的性质和模运算的性质,大大减少了计算量。它不仅适用于大整数的幂运算,还可以在模运算中高效地计算结果,是解决相关问题的重要工具。
补充:对于py中的np.dot
np.dot 是 NumPy 库中的一个函数,用于计算两个数组的点积(dot product)。它是一个非常强大的函数,可以处理向量、矩阵以及更高维度数组的乘法运算。以下是对 np.dot 的详细解释和一些常见用法。
1. 点积的基本概念
点积(dot product)是线性代数中的一个基本运算,用于计算两个向量的乘积。对于两个向量 a 和 b,它们的点积定义为:
a⋅b=i=1∑naibi
其中 ai 和 bi 是向量的对应元素。
对于矩阵,点积通常表示为矩阵乘法。如果 A 是一个 m×n 矩阵,B 是一个 n×p 矩阵,那么它们的点积 C=A⋅B 是一个 m×p 矩阵,其中每个元素 Cij 由以下公式计算:
Cij=k=1∑nAikBkj
2. np.dot 的用法
np.dot 可以处理多种类型的数组,包括一维数组(向量)、二维数组(矩阵)以及更高维度的数组。它的行为会根据输入数组的维度而有所不同。
2.1 向量点积
如果输入是两个一维数组,np.dot 计算它们的点积。
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
result = np.dot(a, b)
print(result) # 输出:32 (1*4 + 2*5 + 3*6)
2.2 矩阵乘法
如果输入是两个二维数组,np.dot 计算它们的矩阵乘积。
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
result = np.dot(A, B)
print(result)
# 输出:
# [[19 22]
# [43 50]]
2.3 多维数组
对于更高维度的数组,np.dot 的行为会更复杂。它会沿着最后一个轴进行点积运算。
A = np.random.rand(2, 3, 4)
B = np.random.rand(2, 4, 5)
result = np.dot(A, B)
print(result.shape) # 输出:(2, 3, 5)
3. np.dot 与 @ 运算符
从 Python 3.5 开始,@ 运算符被引入,用于表示矩阵乘法。在 NumPy 中,@ 运算符与 np.dot 的行为相同。
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
result = A @ B # 等价于 np.dot(A, B)
print(result)
# 输出:
# [[19 22]
# [43 50]]
4. 注意事项
- 维度匹配:
- 对于向量点积,两个数组的长度必须相同。
- 对于矩阵乘法,第一个矩阵的列数必须等于第二个矩阵的行数。
- 对于更高维度的数组,最后一个轴的维度必须匹配。
- 性能优化:
- NumPy 的
np.dot是高度优化的,底层使用了 BLAS(Basic Linear Algebra Subprograms)库,因此在处理大规模数据时非常高效。
- NumPy 的
- 与
np.matmul的区别:np.dot和np.matmul在处理二维数组时行为相同,但在处理一维数组时有所不同。np.matmul会将一维数组视为二维数组(列向量或行向量),而np.dot则直接计算点积。
5. 总结
np.dot 是 NumPy 中用于计算点积和矩阵乘法的核心函数。它支持多种输入维度,并且在性能上经过高度优化。如果你需要进行线性代数运算,np.dot 是一个非常强大的工具。
Day3
学小程序去了.......
Day4 贪心
1.分组问题
题目描述
有 n 组学生,给出初始时每组中的学生个数,再给出每组学生人数的上界 RR 和下界 L (L≤R),每次你可以在某组中选出一个学生把他安排到另外一组中,问最少要多少次才可以使 N 组学生的人数都在 [L,R][L,R] 中。
输入格式
第一行一个整数 n,表示学生组数;
第二行 n个整数,表示每组的学生个数;
第三行两个整数 L,R,表示下界和上界。
输出格式
一个数,表示最少的交换次数,如果不能满足题目条件输出 −1−1。
算法思路
- 可行性检查:
- 首先,计算所有组的总学生数 S。
- 检查 S 是否满足 n *L≤S≤n *R。如果不满足,直接返回 -1,因为无法通过移动学生满足条件。
- 计算调整需求:
- 遍历每组学生人数 ai,计算每 组与范围 [L,R] 的偏差:
- 如果 ai<L,则该组需要增加 L−ai 个学生,记为 负偏差(
deficit)。 - 如果 ai>R,则该组需要减少 ai−R 个学生,记为 正偏差(
excess)。
- 如果 ai<L,则该组需要增加 L−ai 个学生,记为 负偏差(
- 遍历每组学生人数 ai,计算每 组与范围 [L,R] 的偏差:
- 计算最小移动次数:
- 每次移动操作可以同时解决一个正偏差和一个负偏差(即从一个组移出一个学生,移到另一个组)。
- 最小移动次数为
max(deficit, excess),因为:- 如果
deficit > excess,则需要从其他组中分配额外的学生来满足需求。 - 如果
excess > deficit,则需要将多余的excess分配到需要的学生中。
- 如果
- 如果
deficit == excess,则所有偏差都可以完美匹配,移动次数为deficit。
关键点
- 可行性检查:确保总学生数 S 在理论上的可行范围内。
- 偏差计算:通过计算正偏差和负偏差,确定需要调整的学生数量。
- 最小移动次数:通过最大化正偏差和负偏差的匹配,最小化移动次数。
代码实现
以下是完整的 Python 代码实现:
def min_moves_to_balance_groups(n, groups, L, R):
# 计算总学生数
total_students = sum(groups)
# 检查是否可行
if n * L > total_students or total_students > n * R:
return -1 # 不可能满足条件
# 初始化正偏差和负偏差
excess = 0 # 需要移出的学生总数
deficit = 0 # 需要移入的学生总数
# 计算每个组的调整需求
for group in groups:
if group < L:
deficit += L - group # 负偏差
elif group > R:
excess += group - R # 正偏差
# 最小移动次数为正偏差和负偏差的最大值
moves = max(deficit, excess)
return moves
# 读取输入
n = int(input().strip())
groups = list(map(int, input().strip().split()))
L, R = map(int, input().strip().split())
# 调用函数并输出结果
result = min_moves_to_balance_groups(n, groups, L, R)
print(result)
示例
输入:
复制
2
10 20
10 15
输出:
5
解释:
- 第一组学生数为 10,不需要调整(10≥L)。
- 第二组学生数为 20,需要减少 5 个学生(20−R=5)。
- 最小移动次数为 5,即将 5 个学生从第二组移动到第一组。
总结
这个算法的核心在于通过计算正偏差和负偏差,找到最小的移动次数来平衡所有组的学生人数。通过可行性检查和贪心策略,我们能够高效地解决这个问题,时间复杂度为 O(n)。
2.纸牌均分
有 N 堆纸牌,编号分别为1,2,…,N。每堆上有若干张,但纸牌总数必为 N 的倍数。可以在任一堆上取若干张纸牌,然后移动。
移牌规则为:在编号为 11 堆上取的纸牌,只能移到编号为 22 的堆上;在编号为 NN 的堆上取的纸牌,只能移到编号为N−1 的堆上;其他堆上取的纸牌,可以移到相邻左边或右边的堆上。
现在要求找出一种移动方法,用最少的移动次数使每堆上纸牌数都一样多。
例如 N*=4 时,4 堆纸牌数分别为 9,8,17,6。
移动 3 次可达到目的:
- 从第三堆取 4 张牌放到第四堆,此时每堆纸牌数分别为 9,8,13,10。
- 从第三堆取 3 张牌放到第二堆,此时每堆纸牌数分别为 9,11,10,10。
- 从第二堆取 1 张牌放到第一堆,此时每堆纸牌数分别为 10,10,10,10。
输入格式
第一行共一个整数 NN,表示纸牌堆数。 第二行共 NN 个整数 A1,A2,…,ANA1,A2,…,A**N,表示每堆纸牌初始时的纸牌数。
输出格式
共一行,即所有堆均达到相等时的最少移动次数。
为了解决这个问题,我们需要找到一种方法,使得每堆纸牌的数量最终都相等,并且移动次数最少。我们可以通过以下步骤来实现:
- 计算平均值:首先,计算所有纸牌的总数,然后除以堆数 N,得到每堆纸牌最终应该有的平均数量。
- 确定移动方向:根据规则,纸牌只能移动到相邻的堆上。因此,我们需要从每堆纸牌的数量与平均值的差值出发,确定纸牌的移动方向。
- 最小移动次数:为了最小化移动次数,我们应优先考虑将纸牌从数量较多的堆移动到数量较少的堆,直到所有堆的数量都达到平均值。
解题步骤
计算平均值:
平均值=N∑i=1NAi
确定移动方向:
- 对于每堆纸牌,计算其与平均值的差值。
- 如果某堆纸牌的数量大于平均值,需要将多余的纸牌移动到相邻的堆上。
- 如果某堆纸牌的数量小于平均值,需要从相邻的堆上移动纸牌过来。
最小移动次数:
- 从左到右遍历每堆纸牌,记录每堆纸牌与平均值的差值。
- 使用一个变量
balance来记录当前堆与前一堆的平衡状态。 - 每次移动纸牌时,更新
balance,并增加移动次数。
代码实现
def min_moves_to_equalize_cards(N, A):
# 计算平均值
total_cards = sum(A)
average = total_cards // N
# 初始化移动次数和平衡变量
moves = 0
balance = 0
# 遍历每堆纸牌
for i in range(N):
# 计算当前堆与平均值的差值
diff = A[i] - average
# 更新平衡变量
balance += diff
# 如果平衡变量不为零,说明需要移动纸牌
if balance != 0:
moves += 1
return moves
# 读取输入
N = int(input())
A = list(map(int, input().split()))
# 计算并输出最小移动次数
print(min_moves_to_equalize_cards(N, A))
示例
对于给定的示例 N=4 和 A=[9,8,17,6]:
计算平均值:
平均值=49+8+17+6=10
确定移动方向:
- 第一堆:9−10=−1(需要从第二堆移动 1 张纸牌)
- 第二堆:8−10=−2(需要从第相邻堆移动 2 张纸牌)
- 第三堆:17−10=7(需要移动 7 张纸牌到相邻堆)
- 第四堆:6−10=−4(需要从第三堆移动 4 张纸牌)
最小移动次数:
- 从第三堆移动 4 张纸牌到第四堆
- 从第三堆移动 3 张纸牌到第二堆
- 从第二堆移动 1 张纸牌到第一堆
总共需要 3 次移动。
输出:3
Day5 递推
通过简单的暴力dfs递归方式,时间复杂度过高,虽然可以定义数组来记忆每次的结果,给暴力搜索数”减枝“,但是时间复杂度仍然很高。
递归的过程分为”递“和”归“,如果将递归的过程只保留”归“的过程,便可以大大降低时间复杂度。
这便是递推,下面简单演示一下斐波那契的优化
同时也是跳台阶问题
DP核心:找变量之间的状态转移方程
跳台阶问题
n级台阶,一次可以选择跳一级或者两级,问有几种跳跃方式?
分析
自然是斐波那契数列,f(n)表示n级台阶的跳跃方式数,如果n级台阶,对于最后一跳,如果是跳一级,那跳跃方式数就是f(n-1),如果是跳两级,跳跃方式数就是f(n-2),那么最后一跳总共就这两种情况,则f[i] = f[i - 1] + f[i - 2]
代码
# 简单的递归搜索加上记忆化搜索,时间复杂度仍然很高
def jump(n):
# 如果n在记忆中,就直接返回
if n in mem:
return mem[n]
if n == 1:
sum = 1
elif n == 2:
sum = 2
else:
sum = jump(n - 1) + jump(n - 2)
mem[n] = sum
return sum
"""利用递归过程中的“推”的过程,便是基本的递推优化"""
"""注意,这里是优化时间"""
def optimized_jump(n):
f = [0] * (n + 1)
f[1] = 1
f[2] = 2
for i in range(3, n + 1):
f[i] = f[i - 1] + f[i - 2] # 这个递推公式也就是dfs的状态转移公式
return f[n]
# 上面的代码也可以换成这种形式的写法,核心都是从小到大递推
"""注意,这里是对上面的函数优化空间"""
def optimized_jump2(n):
if n == 1: return 1
if n == 2: return 2
newf = 0
temp1 = 1
temp2 = 2
for i in range(3, n + 1):
newf = temp1 + temp2
temp1 = temp2
temp2 = newf
return newf
if __name__ == '__main__':
mem = [0] * 100
# 明显快了很多
# print("Starting:" ,jump(400))
# print("Starting:", optimized_jump(400))
print("Starting:", optimized_jump2(300))
大盗阿福
阿福洗劫商店,不能同时洗劫相邻的两家商店,求最多能洗劫多少钱
输入第一行是商店数T,第二行T个数,表示每家商店的现金数目
输出能取得的最大金钱数
分析
该问题目前可以两中方式解决。T是商店数,moneyList是每个商店的金钱数,自然 $$ moneyList[T-1]就是最后一家的金钱数 $$
背包
对于这个问题,自然而然可以联想到Day1的背包问题,要收益最大,就依次分析情况
定义函数max_money(T)表示有T家店铺时的最优解。
如果商店数只有一个(T == 1),那只洗劫它一个(moneyList[0]),如果有两个,就洗劫两者之中最大那个
如果大于两个的店铺,对于有第T家店铺的情况,就开始考虑,是直接使用有T-1家店铺情况时候的最优解(max_money(T - 1)),还是使用有T-2家店铺的时候的最优解,并且窃取这多出来的第T家店铺这个店铺(max_money(T - 2) + moneyList[T - 1])。
# 考虑01背包问题的解决方式
def max_money(T):
if T == 1:
return moneyList[0]
if T == 2:
return max(moneyList[0], moneyList[1])
# moneylist[T-1]是最后一个店铺的金钱数,这里考虑的问题就是,如果多一个店铺,是在原有基础上保留,还是退回一个店铺选择窃取这个新出现的店铺
return max(max_money(T - 2) + moneyList[T - 1], max_money(T - 1))
递归
然后对于是递归,定义函数dfs(x)表示阿福正在考虑第x家店铺,递推的边界(结束条件)就是当x大于等于商店数,此时第x个商店不存在,就返回0。
注意这里有个小坑,moneyList[x-1]才是表示第x家店铺的金钱数,第一家店铺的金钱数是存在moneyList[0]的,别搞混了。
当x为1 的情况下,就考虑最大收益,是就洗劫第这家店铺(moneyList(x-1)),同时因为限制去考虑相隔一家的店铺(dfs(x+2)), 还是不洗这家店铺,去考虑相邻的那家店铺dfs(x + 1)。这两个取最大就行
倘若选择了dfs(x+2)+moneyList(x-1),那就说明了阿福已经洗劫了第x家店铺,因为要相隔一个的限制,阿福开始考虑对于第x+2家店铺,是洗劫它并去考虑它的下下家店铺,还是放弃它去考虑它相邻的那家店铺,以此递推下去,直到阿福考虑的第x家店铺并不存在,无法洗劫,现金为0.
# 考虑递推优化的方式
"""当遇到第x家店铺时,考虑的是选择下一家(x+1)店铺dfs(x + 1)或者就选择这一家,那么下次考虑的就是第x+2家店铺dfs(x + 2) + moneyList[x]"""
def dfs(x):
if x > T: return 0
return max(dfs(x + 1), dfs(x + 2) + moneyList[x-1])
记忆化搜索优化递归
自然直接递归的方式形成的搜索树是许多重复的,需要进行“减枝”的操作。那便要使用记忆化搜索
对于记忆化搜索,函数的形参要尽量少,对于不影响递归边界的参数就没必要传入函数,如moneyList,直接在main函数里面定义就行,python会自动处理为全局的变量,函数中可以直接读取使用。
定义记账本mem = [0] * (T + 1),当考虑第x个店铺时,如果已经计算过最优解并存在mem中(mem[x]!=0)那便直接返回就行。如果没有再继续计算,将每次函数运行计算得到的结果存在sum中。
这里的mem[x]表示的就是对于T家店铺,如果只从第x家开始考虑,能取得的最大金钱数。
mem[1]相当于就是dfs(1),表示的就是从第一家开始考虑,也就是考虑所有的T家店铺能得到的最大金钱数。
mem = [0] * (T + 2) #如此定义长度是为了防止x > T的情况出现,大于T的时候自然存0就行
def memSearch(x):
if mem[x] != 0:
return mem[x]
if x > T:
sums = 0
else:
sums = max(dfs(x + 1), dfs(x + 2) + moneyList[x - 1])
mem[x] = sums
return sums
递推
以上方法都只是利用“归”的方式来产生答案,那么我们完全可以避免那“递”的过程,直接进行递推。
f[i] 表示从第i个店铺开始洗劫能获取的最大现金数,其实跟mem[i]一个意思
f[i] = max(f[i + 1], f[i + 2] + moneyList[i - 1])表示 从第i个店铺开始能获取到的最大价值是两种情况中的最大值
第一张情况是洗劫第i个店铺,那就是从第i+2个店铺开始能获取的最大价值加上第i个店铺的价值f[i + 1], f[i + 2]
第二种情况是不洗劫第i个店铺,那么从第i个店铺开始能获取到的最大价值等于从第i+1个店铺开始能获取到的最大价值
注意这里f = [0] * (T + 3)是因为为了防止i==T 时 f[i + 2]不越界
f = [0] * (T + 3) # f[i] 表示从第i个店铺开始洗劫能获取的最大现金数
def recursFind(T):
# 从T到1倒叙进行
for i in range(T, 0, -1):
f[i] = max(f[i + 1], f[i + 2] + moneyList[i - 1])
return f[1]
递推空间优化
我们只需要f列表中的一个值,而这个又是满足规律的,即T个商店能获取的最大价值是T-1个商店能获取的最大价值与T-2个商店能获取的最大价值同第T个商店的价值的最大值。
MaxMon[T] = max(MaxMon[T-1],MaxMon[T]+moneyList[i])
这便是状态转移方程。当前值只与前一个值和前前个值有关,那么定义三个变量,一个表示当前值(newf ),一个表示前一个值(temp1 ),另一个表示前前值(temp12),三个变量轮流更新就行。
def recursFindPlus(T):
newf = 0
temp1 =0
temp2 = 0
for i in range(T):
newf = max(temp1, temp2 + moneyList[i])
temp2 = temp1
temp1 = newf #temp1始终存的是上一次的最优的结果,temp2存的是上上次的最优结果
print("newf:",newf)
return newf
基本规律
完整代码
# 考虑01背包问题的解决方式
def max_money(T):
if T == 1:
return moneyList[0]
if T == 2:
return max(moneyList[0], moneyList[1])
# moneylist[T-1]是最后一个店铺的金钱数,这里考虑的问题就是,
# 如果多一个店铺,是在原有基础上保留,还是退回一个店铺选择窃取这个新出现的店铺
return max(max_money(T - 2) + moneyList[T - 1], max_money(T - 1))
# 考虑递归的方式
"""当遇到第x家店铺时,考虑的是选择下一家(x+1)店铺dfs(x + 1)或者就选择这一家,
那么下次考虑的就是第x+2家店铺dfs(x + 2) + moneyList[x]"""
def dfs(x):
if x > T:
return 0
return max(dfs(x + 1), dfs(x + 2) + moneyList[x - 1])
# 记忆化搜索优化递归
def memSearch(x):
if mem[x] != 0:
return mem[x]
if x > T:
sums = 0
else:
sums = max(dfs(x + 1), dfs(x + 2) + moneyList[x - 1])
mem[x] = sums
return sums
# 倒叙的递推
def recursFind(T):
# 从T到1倒叙进行
for i in range(T, 0, -1):
f[i] = max(f[i + 1], f[i + 2] + moneyList[i - 1])
return f[1]
# 递推并且进行空间优化
def recursFindPlus(T):
temp1 = 0
temp2 = 0
newf = 0
for i in range(T):
newf = max(temp1, temp2 + moneyList[i])
temp2 = temp1
temp1 = newf # temp1始终存的是上一次的最优的结果,temp2存的是上上次的最优结果
print("newf:", newf)
return newf
if __name__ == '__main__':
T = int(input())
moneyList = list(map(int, input().split(" ")))
print(max_money(T))
print(dfs(1))
mem = [0] * (T + 2)
print(memSearch(1))
f = [0] * (T + 3) # f[i] 表示从第i个店铺开始洗劫能获取的最大现金数
print(recursFind(T))
print(recursFindPlus(T))
注意mian函数内定义的已经是全局变量所以其他函数中可以直接拿来使用
三角寻路
输入r为行数,然后输入r行,第i行有i个数,构成三角
问从三角最顶部开始寻路依次往下走,走过的路程的最大长度是多少?(每次只能走左右两边)
注意点
注意f[i] [j]表示以i行j列为终点的路径的最长路径和
注意递推空间的优化
状态转移方程: $$ f[i][j] = max(f[i + 1][j], f[i + 1][j + 1]) + tangleList[i - 1][j - 1] $$ 注意f[i] [j]是表示表示以第i行第j列为终点产生的最大的路径和,tangleList[i - 1] [j - 1] 是第i行第j列的值(从第一行开始的)
因为第i行第j列的状态只是由上一个的状态转移过来的,i是有规律一直往下的 则 f_s[j] = max(f_s[j], f_s[j + 1]) + tangleList [i - 1] [j - 1]就表示上一行的第j列的最优与第j+1列的最优的最大值加上当前i行j列的值
同样还是三个函数
代码
# dfs存坐标,控制访问的边界
def dfs(x, y):
if x > r or y > r:
return 0
# 求最优的子问题,
# 就是看往左dfs(x + 1, y)或者往右dfs(x, y + 1)的最大值,
# 记得加上当前值tangleList[x][y](因为算的是和)
return max(dfs(x + 1, y), dfs(x + 1, y + 1)) + tangleList[x - 1][y - 1]
# 记忆化搜索优化
def dfs_mem(x, y):
if mem[x][y] != 0:
return mem[x][y]
sums = 0
if x > r or y > r:
sums = 0
# 求最优的子问题,
else:
sums = max(dfs_mem(x + 1, y), dfs_mem(x + 1, y + 1)) + tangleList[x - 1][y - 1]
mem[x][y] = sums # 记录值
# print(mem)
return sums
# 递推优化
# 从下往上推,第一个点一定是终点
def dp():
for i in range(r, 0, -1):
for j in range(1,i+1):
f[i][j] = max(f[i + 1][j], f[i + 1][j + 1]) + tangleList[i - 1][j - 1]
# print(" :", f)
return f[1][1]
# 从上往下推最后一个点不一定,但是起点一定是第一个点1,1
# f[i][j]就表示以第i行第j列为终点产生的最大的路径和,而题目只要求到达底部的最大路径所以说要找底部f[r]中的最大值
def dp_reverse():
for i in range(1,r+1):
for j in range(1,i+1):
f[i][j] = max(f[i - 1][j], f[i - 1][j - 1]) + tangleList[i - 1][j - 1]
# print(" :", f)
return max(f[r])
# 递推空间优化
# 因为第i行第j列的状态只是由上一个的状态转移过来的,i是有规律一直往下的
# 则 f_s[j] = max(f_s[j], f_s[j + 1]) + tangleList[i - 1][j - 1]就表示上一行的第j列的最优与第j+1列的最优的最大值加上当前i行j列的值
def dp_space():
for i in range(r, 0, -1):
for j in range(1,i+1):
f_s[j] = max(f_s[j], f_s[j + 1]) + tangleList[i - 1][j - 1]
return f_s[1]
if __name__ == '__main__':
r = int(input())
tangleList = [[0] * r for i in range(r)]
# 输入三角
for i in range(r):
tangleList[i] = list(map(int, input().split())) + [0] * (r - i + 1)
# print(tangleList)
mem = [[0] * (i + 2) for i in range(r+2)]
print(dfs_mem(1, 1))
# f = [[0] * (r + 2) for i in range(r + 2)]
# print(dp())
f = [[0] * (r + 2) for i in range(r + 2)]
print(dp_reverse())
f_s = [0] * (r + 2)
print(dp_space())
# print(dp_space2())
补充:日期计算
输入两个日期,返回日期之间的分钟数间隔
代码
from datetime import datetime
def calculate_time_difference():
# 定义时间格式
time_format = "%Y-%m-%d-%H:%M"
# 提示用户输入两个时间
time_str1 = input("请输入第一个时间(格式:YYYY-MM-DD-HH:MM):")
time_str2 = input("请输入第二个时间(格式:YYYY-MM-DD-HH:MM):")
try:
# 将时间字符串转换为datetime对象
time1 = datetime.strptime(time_str1, time_format)
time2 = datetime.strptime(time_str2, time_format)
# 计算两个时间之间的差值(timedelta对象)
time_difference = time2 - time1
# 将时间差转换为分钟数
minutes_difference = time_difference.total_seconds() / 60
# 输出结果
print(f"两个时间之间的分钟数间隔为:{minutes_difference}分钟")
except ValueError as e:
print("输入的时间格式不正确,请确保格式为YYYY-MM-DD-HH:MM。错误信息:", e)
# 调用函数
calculate_time_difference()
程序说明:
- 用户输入:
- 使用
input()函数提示用户输入两个时间字符串。 - 用户需要按照指定的格式(
YYYY-MM-DD-HH:MM)输入时间。
- 使用
- 异常处理:
- 使用
try-except块来捕获可能的错误,例如输入的时间格式不正确。 - 如果输入格式错误,程序会提示用户并显示错误信息。
- 使用
- 时间计算:
- 将输入的时间字符串转换为
datetime对象。 - 计算两个时间之间的差值,并将其转换为分钟数。
- 将输入的时间字符串转换为
示例运行:
假设用户输入以下时间:
复制
请输入第一个时间(格式:YYYY-MM-DD-HH:MM):2007-06-23-11:59
请输入第二个时间(格式:YYYY-MM-DD-HH:MM):2007-06-23-12:00
程序输出:
两个时间之间的分钟数间隔为:1.0分钟
如果用户输入的时间格式不正确,例如输入了2007-06-23-11:5,程序会提示:
输入的时间格式不正确,请确保格式为YYYY-MM-DD-HH:MM。错误信息: time data '2007-06-23-11:5' does not match format '%Y-%m-%d-%H:%M'
这个程序可以灵活处理用户输入的时间,并计算出两个时间之间的分钟数间隔。
Day6 动态规划递推复习
最少花费跳楼梯
给你一个整数数组
cost,其中cost[i]是从楼梯第i个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。输入n,n为cost列表的长度,自然楼梯是从第0层到第n-1层
你可以选择从下标为
0或下标为1的台阶开始爬楼梯。直到你处于第n层的时候,你才真正达到顶端,结束。
请你计算并返回达到楼梯顶部的最低花费。
分析
还是原来昨天那牢三样,递归,记忆化搜索,递推。
核心要点是抓住状态转移方程,多定义列表,如定义了f[i],那么f[i]代表的含义是什么,他会参与怎样的运算,它与临近的元素之间满足什么关系,边界在哪。
代码
# 简单暴力
def solve(x):
# 若超过最大台阶数n-1,即处于第n个或者更大,说明已经到达顶部,则返回0
if x == 0 or x == 1:
return 0
else: # 考虑最后一步,最后一步是跨2层的能量低一点还是跨1层能量低一点
return min(solve(x - 1) + cost[x - 1], solve(x - 2) + cost[x - 2])
# 记忆化搜索优化
def solve_mem(x):
if (mem[x] != 0):
return mem[x]
if x == 0 or x == 1:
sums = 0
else:
sums = min(solve(x - 1) + cost[x - 1], solve(x - 2) + cost[x - 2])
# 利用sums存变量并返回结果
mem[x] = sums
return sums
# 递推优化
def cursion_solve(x):
# 到第n层就结束,f[i]表示的就是从开始到第i层的最小消费
for i in range(2,x+1): # 从顶部n开始向下
# 要包含第2层并且不考虑第0和1层的消费(因为可以直接选从0或者1开始,自然是0)
# i 从2开始 ,f[2]就表示从开始到第三层的最小消费,自然是min(f[i - 1] + cost[i - 1], f[i - 2] + cost[i - 2])
f[i] = min(f[i - 1] + cost[i - 1], f[i - 2] + cost[i - 2])
# print(f)
# 返回f[n]表示从开始到第n层的最小消费
return f[n]
if __name__ == '__main__':
# 总共0到n-1层楼梯
n = int(input())
# cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用
cost = list(map(int, input().split(' ')))
# solve(x)表示的是从第x层开始到顶能取得的最大数
print(solve(n))
mem = [0] * (n + 1)
print(solve_mem(n))
# f[i]表示从第i层开始到达顶部的最小花费
f = [0] * (n + 1)
print(cursion_solve(n))
最长子序列
给定数组,寻找数组中最长的递增的子序列的长度
代码:
# 递归加记忆化搜索
def L(x):
if x in memo:
return memo[x]
if x == len(num) - 1:
return 1
max_len = 1
for i in range(x + 1, len(num)):
if num[i] > num[x]:
# 与以下一个点为起点的最短路径长度进行比较并做更新
max_len = max(max_len, L(i) + 1)
memo[x] = max_len
return max_len
def recursion_search():
n = len(num) # 获取数组长度
f = [1] * n # 初始化数组,每个位置的最长递增子序列长度至少为1
for x in range(n): # 遍历每个位置
for i in range(x): # 检查所有小于x的位置
if num[x] > num[i]: # 如果当前元素大于之前的某个元素
f[x] = max(f[x], f[i] + 1) # 更新以x为结尾的最长递增子序列长度
return max(f) # 返回最长递增子序列的最大长度
if __name__ == '__main__':
n = int(input())
num = list(map(int, input().split(' ')))
"""定义哈希表存储以x为起点的最大路径长度"""
memo = {}
print(L(0)) # 最长递增子序列为1,2,3,4,5长度为5
f = [0] * (n + 1) # f[i]表示以num[i]结尾的最长子序列长度
print(recursion_search()) # 最长递增子序列为1,2,3,4,5长度为5
方法总结
- 重述问题:问题要求干什么
- 找到最后一步
- 去掉最后一步,问题变成了什么
- 定义列表,写状态转移方程
Day15背包问题进阶
二维限定背包
有N 件物品和一个容量是V 的背包,背包能承受的最大重量是 M。
每件物品只能用一次。体积是 vi,重量是 mi,价值是 wi。
求解将哪些物品装入背包,可使物品总体积不超过背包容量,总重量不超过背包可承受的最大重量,且价值总和最大。 输出最大价值。
输入格式
第一行三个整数,N,V,M,用空格隔开,分别表示物品件数、背包容积和背包可承受的最大重量。
接下来有N 行,每行三个整数 vi,mi,wi,用空格隔开,分别表示第 ii 件物品的体积、重量和价值。
输出格式
输出一个整数,表示最大价值。
数据范围
0<N≤10000<N≤1000 0<V,M≤1000<V,M≤100 0<vi,mi≤1000<vi,mi≤100 0<wi≤1000
分析
还是老一套,只是加了限制条件,递归到记忆化搜索到递推到二维优化
代码
def dfs(x, spV, spM):
if x > N:
return 0
# 若装不下当前物品,就继续看下一个物品
if spV < vlist[x] or spM < mlist[x]:
return dfs(x + 1, spV, spM)
# 若装得下当前物品,就看看能得到的最大价值
# 就是看看在不装当前物品的情况下,能得到的最大价值,和装当前物品的情况下,能得到的最大价值
return max(dfs(x + 1, spV, spM), wlist[x] + dfs(x + 1, spV - vlist[x], spM - mlist[x]))
def dfs_mem(x, spV, spM):
# 若之前的状态有记录,就直接返回
if mem[x][spV][spM] != 0:
return mem[x][spV][spM]
if x > N:
return 0
sums = 0
# 若装不下当前物品,就继续看下一个物品
if spV < vlist[x] or spM < mlist[x]:
sums = dfs(x + 1, spV, spM)
else:
sums = max(dfs(x + 1, spV, spM), wlist[x] + dfs(x + 1, spV - vlist[x], spM - mlist[x]))
mem[x][spV][spM] = sums
return sums
def dfs_dp():
# i代表当前是考虑第i个物品,j代表当前的剩余体积,k代表当前剩余重量
for i in range(N, 0, -1):
for j in range(V + 1):
for k in range(M + 1):
# j代表当前的剩余体积,k代表当前剩余重量,有一个被超了就无法装下物品
# 那么等同于不装这个物品,考虑从第x+1个物品开始,剩余体积重量不减的最优解
if j < vlist[i] or k < mlist[i]:
dp[i][j][k] = dp[i + 1][j][k]
else:
# 能装下,就考虑,是装下这个物品,考虑本物品价值加上考虑从第x+1个物品开始剩余体积重量对应减去本物品的体积重量的最优解
# 还是不装这个物品,考虑从第x+1个物品开始,剩余体积重量不减的最优解
# 即,如果装了第x个物品,那么从第x+1个物品开始的剩余体积重量当然少
dp[i][j][k] = max(dp[i + 1][j][k], wlist[i] + dp[i + 1][j - vlist[i]][k - mlist[i]])
# dp[1][V][M]表示从第1个物品开始考虑,此时剩余体积是V剩余重量M,得到的最优价值
return dp[1][V][M]
def dfs_dp_reverse():
for i in range(1, N + 1):
for j in range(V + 1):
for k in range(M + 1):
if j < vlist[i] or k < mlist[i]:
dp[i][j][k] = dp[i - 1][j][k]
else:
dp[i][j][k] = max(dp[i - 1][j][k], wlist[i] + dp[i - 1][j - vlist[i]][k - mlist[i]])
return dp[N][V][M]
# 二维优化
def dfs_dp_two():
for x in range(1, N + 1):
for j in range(V, vlist[x]-1 , -1):
for k in range(M, mlist[x] -1, -1):
dp_two[j][k] = max(dp_two[j][k], wlist[x] + dp_two[j - vlist[x]][k - mlist[x]])
return dp_two[V][M]
if __name__ == '__main__':
N, V, M = map(int, input().split(' '))
# 先初始化第0个物品的体积重量价值为0
vlist = [0] # 体积数列
mlist = [0] # 重量数列
wlist = [0] # 价值数列
for _ in range(N):
v, m, w = map(int, input().split(' '))
vlist.append(v)
mlist.append(m)
wlist.append(w)
# 记忆化搜索
mem = [[[0] * 1010] * (1010) for _ in range(1010)]
print(dfs_mem(1, V, M))
# 动态规划
dp = [[[0] * (M + 2) for _ in range(V + 2)] for _ in range(N + 2)]
print(dfs_dp())
# 二维优化
dp_two = [[0] * (M + 2) for _ in range(V + 2)]
print(dfs_dp_two())
二维优化
重点讲讲二维优化,这里是正向的二维优化,x在外层,对于第x个物品,剩余体积j重量k的背包能容纳的最大价值
要么是不接受该物品时的最大价值dp_two[j][k](因为没有接受该物品,所以背包仍然剩余体积j重量k)
$$ 要么是接受该物品时的最大价值wlist[x] + dp_two[j - vlist[x]][k - mlist[x]] $$ (因为接受了该物品,所以背包剩余体积j- vlist[x]重量k- mlist[x]),则最大价值为体积j- vlist[x]重量k- mlist[x]的背包能创造的最大价值加上第x物品的价值
def dfs_dp_two():
for x in range(1, N + 1):
for j in range(V, vlist[x]-1 , -1):
for k in range(M, mlist[x] -1, -1):
dp_two[j][k] = max(dp_two[j][k], wlist[x] + dp_two[j - vlist[x]][k - mlist[x]])
return dp_two[V][M]
注意这里对于j,k的遍历,表示此时背包剩余体积j 剩余重量k,那么自然j 得大于等于当前物品的体积,k要大于等于当前物品的重量
所以注意倒叙循环的边界range(V, vlist[x]-1 , -1),最少能取到vlist[x]
完全背包问题
完全背包问题与01背包的区别在于对于某个物品,数量是无线的,本次选了这个物品之后,下次还可以继续选
分析
那么下次还可以选的话,第二种情况就不必跳到下一个物品
那么状态转移方程就变成了 $$ m[i][j] = max(m[i + 1][j], m[i][j - vlist[i]] + wlist[i])
$$
$$ ————————————m[i][j]表示考虑第i个物品剩余容量为j时的最大物品价值 $$
全部代码
# x表示当前枚举到哪个物品,spV表示背包当前剩余的容量
def solve(x, spV):
sums = 0
if f[x][spV] != 0:
return f[x][spV]
if x > N:
return 0
if spV < vlist[x]:
# 当前物品体积超过剩余,就看下一个
sums = solve(x + 1, spV)
else:
# 没有超,开始公式看能否取出当前物品,不取当前物品就考虑下一个物品,取了当前物品,下次还可以考虑当前物品
sums = max(solve(x + 1, spV), solve(x, spV - vlist[x]) + wlist[x])
f[x][spV] = sums
return f[x][spV]
def solve2():
for i in range(N, 0, -1):
for j in range(0, V + 1):
if j < vlist[i]:
m[i][j] = m[i + 1][j]
else:
m[i][j] = max(m[i + 1][j], m[i][j - vlist[i]] + wlist[i])
# print(m)
return m[1][V]
def solve3():
for i in range(1, N + 1):
for j in range(vlist[i], V + 1):
t[j] = max(t[j], t[j - vlist[i]] + wlist[i])
# print(m)
return t[V]
if __name__ == '__main__':
N, V = map(int, input().split(' '))
vlist = [0]
wlist = [0]
for i in range(N):
v, w = map(int, input().split(' '))
vlist.append(v)
wlist.append(w)
# print(vlist,wlist)
# 记忆化搜索
f = [[0] * (V + 2) for i in range(N + 2)]
# print(solve(1, V))
# 递推
m = [[0] * (V + 2) for i in range(N + 2)]
print(solve2())
# 空间优化
t = [0 for i in range(V + 2)]
print(solve3())
一维优化
自然可以对递推进行一维优化
我们先看简单01背包一维优化的代码:
"""01背包"""
def solve3():
for i in range(1, N + 1):
for j in range(V, vlist[i] - 1,-1):
t[j] = max(t[j], t[j - vlist[i]] + wlist[i])
# print(m)
return t[V]
01背包倒序枚举体积的目的就是 只让每个物品最多拿一次, 01背包如果正序枚举体积的话,就会让物品被拿多次从而违反规则。
但是完全背包不用考虑这个问题,因为本身就是可以拿多次的!t[j]的值靠前面的值来更新导致物品重复拿取,所以完全背包优化到一维可以正序枚举体积
那么代码自然改成了:
def solve3():
for i in range(1, N + 1):
for j in range(vlist[i], V + 1):
t[j] = max(t[j], t[j - vlist[i]] + wlist[i])
# print(m)
return t[V]
# 空间优化
t = [0 for i in range(V + 2)]
print(solve3())
AI总结
完全背包问题与01背包问题的主要区别在于,每个物品可以被选择多次,而不是只能选择一次。因此,动态规划的状态转移方程和遍历顺序需要相应地调整。
01背包问题与完全背包问题的区别
- 01背包问题:每个物品只能选择一次,因此在更新状态时,需要从大到小遍历体积(逆序),以避免重复计算。
- 完全背包问题:每个物品可以多次选择,因此在更新状态时,需要从小到大遍历体积(正序),以确保每个物品可以多次被选择。
代码分析
以下是你的代码:
def solve3():
for i in range(1, N + 1):
for j in range(vlist[i], V + 1):
t[j] = max(t[j], t[j - vlist[i]] + wlist[i])
return t[V]
1. 变量说明
N: 物品数量。V: 背包的最大容量。vlist: 每个物品的体积。wlist: 每个物品的价值。t: 动态规划数组,t[j]表示背包容量为j时的最大价值。
2. 为什么需要正序枚举体积
在完全背包问题中,每个物品可以被选择多次。如果使用逆序遍历(从大到小),那么每个物品只能被选择一次,这与完全背包问题的定义不符。
关键点:
- 逆序遍历(01背包问题):为了避免重复计算,每次更新状态时,必须确保当前物品只被选择一次。因此,从大到小遍历体积,确保每个物品只被考虑一次。
- 正序遍历(完全背包问题):每个物品可以被选择多次,因此需要从小到大遍历体积,这样在更新状态时,当前物品可以多次被选择。
3. 动态规划的状态转移方程
在完全背包问题中,状态转移方程为: t[j]=max(t[j],t[j−vi]+wi) 其中:
t[j]表示背包容量为j时的最大价值。v_i和w_i分别是第i个物品的体积和价值。
通过正序遍历体积,每次更新 t[j] 时,t[j - v_i] 已经包含了之前所有可能的选择,包括多次选择第 i 个物品的情况。
示例说明
假设:
- 物品数量
N = 2 - 背包容量
V = 5 - 物品体积
vlist = [0, 2, 3](第1个物品体积为2,第2个物品体积为3) - 物品价值
wlist = [0, 3, 4](第1个物品价值为3,第2个物品价值为4)
初始化 t = [0] * (V + 1),即 t = [0, 0, 0, 0, 0, 0]。
第1个物品(体积=2,价值=3)
- 遍历
j从2到5:j = 2:t[2] = max(t[2], t[2 - 2] + 3) = max(0, 0 + 3) = 3j = 3:t[3] = max(t[3], t[3 - 2] + 3) = max(0, 3 + 3) = 3j = 4:t[4] = max(t[4], t[4 - 2] + 3) = max(0, 3 + 3) = 6j = 5:t[5] = max(t[5], t[5 - 2] + 3) = max(0, 3 + 3) = 6
更新后的 t = [0, 0, 3, 3, 6, 6]。
此时t[4]就是包含了两个物品1
第2个物品(体积=3,价值=4)
遍历
j从3到5:j = 3:t[3] = max(t[3], t[3 - 3] + 4) = max(3, 0 + 4) = 4j = 4:t[4] = max(t[4], t[4 - 3] + 4) = max(6, 3 + 4) = 7j = 5:t[5] = max(t[5], t[5 - 3] + 4) = max(6, 3 + 4) = 7
更新后的 t = [0, 0, 3, 4, 7, 7]。
最终结果 t[V] = t[5] = 7,表示背包容量为5时的最大价值为7。
如果为倒叙枚举,那么在遇到小于物品体积的背包体积j之前背包的最大价值都保持是该物品的体积
总结
在完全背包问题中,正序枚举体积是为了确保每个物品可以被多次选择。通过从小到大遍历体积,每次更新状态时,当前物品可以多次被选择,从而满足完全背包问题的定义。
补充:剪绳子问题
给你一根长度为 nn 绳子,请把绳子剪成 mm 段(mm、nn 都是整数,2≤n≤582≤n≤58 并且 m≥2m≥2)。
每段的绳子的长度记为 k[1]、k[2]、……、k[m]k[1]、k[2]、……、k[m]。
k[1]k[2]…k[m]k[1]k[2]…k[m] 可能的最大乘积是多少?
例如当绳子的长度是 88 时,我们把它剪成长度分别为 2、3、32、3、3 的三段,此时得到最大的乘积 1818。
样例
输入:8 输出:18
分析
这个问题可以通过动态规划来解决。我们定义一个函数 f(n),表示长度为 n 的绳子剪成若干段后,各段长度乘积的最大值。我们需要找到 f(n) 的最大值。
首先,我们可以观察到,如果绳子的长度为 2,那么只能剪成两段长度为 1 的绳子,乘积为 1。如果绳子的长度为 3,那么可以剪成两段长度为 1 和 2 的绳子,乘积为 2,或者剪成三段长度为 1 的绳子,乘积为 1,所以最大乘积为 2。
对于长度为 n 的绳子,我们可以尝试剪成两段,其中一段长度为 i(1 ≤ i ≤ n-1),另一段长度为 n-i。那么乘积为 i * f(n-i)。我们需要找到所有可能的 i 中,乘积最大的那个。
通过分析,我们可以发现,当绳子的长度大于 3 时,剪成长度为 3 的段可以得到更大的乘积。这是因为 3 是所有整数中,乘积与和的比值最大的数。所以,我们可以尽量剪成长度为 3 的段,直到剩下的长度小于 3。如果剩下的长度为 2,那么直接剪成两段;如果剩下的长度为 1,那么需要将最后一段长度为 3 的绳子剪成两段长度为 2 的绳子,因为 2* 2 > 3* 1。
所以,while循环的判断条件是是否大于4(等于4的话还是返回4)
根据这个思路,我们可以写出以下代码:
Python代码
class Solution(object):
def maxProductAfterCutting(self,n):
if n == 2:
return 1
if n == 3:
return 2
product = 1
while n > 4:
product *= 3
n -= 3
product *= n
return product
运行这个代码,我们可以得到长度为 8 的绳子剪成若干段后,各段长度乘积的最大值为 18。
Day17 二分
找分界线,左边都是满足某一条件的,右边都是不满足某一条件的
最开始的left和right应该放在数组的两边,这个具体不用看题目具体要求数组是以几开始的。
默认left = -1,right = 数组长度(即默认都视作0开始的,这是因为列表都是0开始的索引,访问时都0开始,如果改成题目要求的索引开始,那访问索引对应元素时又要先修改为0索引开始时对应的索引,太tm麻烦了)
最好都默认索引0开始,最后函数返回结果时候再将索引进行判断改变就行
比如这个题干要求索引1开始,那我函数最后返回时候加一步:
# 检查 right 是否在数组范围内,并且是否等于目标值
if right < len(dataList) and dataList[right] == x:
return right + 1 # 返回索引 + 1
return -1 # 如果未找到,返回 -1
P2249 【深基13.例1】查找
题目描述
输入 n 个不超过 109109 的单调不减的(就是后面的数字不小于前面的数字)非负整数 a1,a2,…,an,然后进行 m 次询问。对于每次询问,给出一个整数 q,要求输出这个数字在序列中第一次出现的编号,如果没有找到的话输出 −1 。
输入格式
第一行 22 个整数 n 和 m,表示数字个数和询问次数。
第二行 n 个整数,表示这些待查询的数字。
第三行 m 个整数,表示询问这些数字的编号,从 11 开始编号。
输出格式
输出一行,m 个整数,以空格隔开,表示答案。
代码
自然,对于要查找的数x,小于它的数都在它右边,属于蓝色(isBlue(num, x)返回true),其他大于等于它的数在它左边,返回false
实际查找那个分界线的过程,就是不断缩小边界线的过程
如果middle属于蓝色的部分,那么将left = middle,即将左边界缩小到middle的位置上,如果middle这个位置不属于蓝色,那么将右边界right缩小到middle的位置上
当left与right相邻时,即left + 1 = right(或者left + 1>= right,一个意思),那么边界线就在left与right之间,即left指向的是最后一个小于x的数,right指向的是第一个大于等于x的数(也就是x第一次出现的索引位置)
需要注意的是,right的值肯定是大于等于0的,但他有可能等于len(dataList) ,这就是要查找的数小于所有数,自然要判断right < len(dataList) 之后再判断dataList[right] == x,两者都成立之后才返回right
那么对应二分查找代码:
def isBlue(num, x):
"""
判断 num 是否小于 x。
:param num: 当前比较的数值
:param x: 目标值
:return: 如果 num < x,返回 True,否则返回 False
"""
return num < x
def binary_search(x, dataList):
"""
使用二分查找算法查找目标值 x 在 dataList 中的位置。
:param x: 目标值
:param dataList: 已排序的数组
:return: 如果找到目标值,返回其索引 + 1;否则返回 -1
"""
left = -1
right = len(dataList) # 确保 right 的值正确
while left + 1 < right:
middle = (right + left) >> 1 # 使用位运算计算中间值,就是向下整除2的意思
if isBlue(dataList[middle], x):
left = middle
else:
right = middle
# 检查 right 是否在数组范围内,并且是否等于目标值
if right < len(dataList) and dataList[right] == x:
return right + 1 # 返回索引 + 1
return -1 # 如果未找到,返回 -1
if __name__ == '__main__':
# 读取输入
n, m = map(int, input().split())
dataList = list(map(int, input().split()))
targetList = list(map(int, input().split()))
# 对每个目标值进行二分查找
for target in targetList:
index = binary_search(target, dataList)
print(index, end=' ')
这题注意要求输出的索引是1开始的,所以你函数最后返回索引的时候要+1
而且,注意最后要检查 right 是否在数组范围内,不然会越界错误
当然位运算那里就是向下整除2的意思。
浮点数求三次方根
题目
输入一个数,返回它的三次方根,要求保留6位小数。测试数据范围为-1000000到1000000
分析
自然用二分,在-100到100之间找到一个分界线,左边的数的三次方都小于x右边的三次方都大于等于x
自然,可写出他的check函数(就是isBlue函数)
def check(num):
return num*num*num < x
自然,二分的步长的10的-8次方,就二分枚举找出答案就行
本质上还是二分查找,不过退出的条件是当left和right之间的距离小于10的-8次方(也就是1e-8),而不是1了。
同时注意无法用位运算,且python中除法保留八位小数要用round(目标数,要保留的位数)函数
代码
def check(num, n):
"""
检查 num 的三次方是否小于 n。
:param num: 当前的中间值
:param n: 目标值
:return: 如果 num^3 < n,返回 True,否则返回 False
"""
return num * num * num < n
def binary_search(n):
"""
使用二分查找算法计算 n 的三次方根。
:param n: 目标值
:return: n 的三次方根,保留8位小数
"""
left, right = -100, 100 # 三次方根的范围
while right - left > 1e-8: # 精度控制
mid = (left + right) / 2 # 计算中间值
if check(mid, n):
left = mid # 如果 mid 的三次方小于 n,更新左边界
else:
right = mid # 否则,更新右边界
result = round(right, 8) # 返回保留8位小数的结果
# 在返回结果时,先将 right 保留8位小数,得到 result。
# 使用字符串格式化:
# 在返回结果时,使用 f"{right:.8f}",这会将 right 格式化为一个字符串,并确保保留8位小数。
# 即使结果是整数或小于8位的小数,也会自动补零
return f"{right:.8f}"
if __name__ == '__main__':
n = eval(input()) # 输入目标值
result = binary_search(n) # 计算三次方根
print(result) # 输出结果
注意在输入n的时候可以是整数也可以是浮点数,所以要利用万能的eval函数优化输入
注意这里不管答案是什么都保留八位小数,那么要使用字符串格式化*:
- 在返回结果时,使用
f"{right:.8f}",这会将right格式化为一个字符串,并确保保留8位小数。即使结果是整数或小于8位的小数,也会自动补零。
整数求三次方根
题目
题目描述
给定正整数 nn,求 n的三次方根。答案向下取整。
输入格式
仅一行,一个正整数 n。
输出格式
仅一行,一个正整数,表示 n的三次方根
。向下取整输出。
分析
老套路,但是答案向下取整,且是正整数,所以用位运算,且循环出口为大于1
同时由于向下取整的问题,要保证数的区间囊括答案区间(1到100000),所以这里我取的数的区间是0到100001
同时注意,这里分界线左边,是blue的部分表示的是三次方小于等于n的数,这样left指向的才是的第一个小于等于n 的数,是一个整数,即使该整数并不是三次方等于n,但它一定是三次方小于n的最大的数,这样也符合了向下取整的题干要求。同时因为返回的是left,且right指向的是比left大1的数,当答案是在边界100000时无法正确返回,所以要设置right的值为100001,这样囊括好了范围不会出现漏掉边缘情况的错误。
代码
def check(num, n):
"""
检查 num 的三次方是否小于 n。
:param num: 当前的中间值
:param n: 目标值
:return: 如果 num^3 < n,返回 True,否则返回 False
"""
return num * num * num <= n
def binary_search(n):
"""
使用二分查找算法计算 n 的三次方根。
:param n: 目标值
:return: n 的三次方根,保留8位小数
"""
left, right = 0, 100001# 三次方根的范围要囊括所有情况(从1到100000)
while right - left > 1: # 精度控制
mid = (left + right)>>1 # 计算中间值
if check(mid, n):
left = mid # 如果 mid 的三次方小于 n,更新左边界
else:
right = mid # 否则,更新右边界
# 使用字符串格式化确保结果保留0位小数
return f"{left:.0f}"
if __name__ == '__main__':
n = int(input()) # 输入目标值
result = binary_search(n) # 计算三次方根
print(result) # 输出结果
银行贷款
题目
题目描述
当一个人从银行贷款后,在一段时间内他(她)将不得不每月偿还固定的分期付款。这个问题要求计算出贷款者向银行支付的利率。假设利率按月累计。
输入格式
三个用空格隔开的正整数。 第一个整数表示贷款的原值 w0,第二个整数表示每月支付的分期付款金额 w,第三个整数表示分期付款还清贷款所需的总月数 m。
输出格式
一个实数,表示该贷款的月利率(用百分数表示),四舍五入精确到 0.1%。数据保证答案不超过 300.0%。
说明/提示
数据保证: $$1≤w_0,w≤2^{31}-1,1≤m≤3000$$
分析
我们首先得明白银行月利率满足的关系: $$ M = P \frac{r(1+r)^n}{(1+r)^n - 1} $$ 那么就直接二分就行,只有r是未知的,我们可以限定r的范围是0到100,由于精度是0.0001,那么循环出口也有了
那么对应的isBlue函数:
def monthly_payment(P, r, n):
"""
计算每月还款数。
:param P: 贷款金额
:param r: 月利率
:param n: 还款总期数
:return: 每月还款数
"""
return P * r * (1 + r) ** n / ((1 + r) ** n - 1)
但是但是,在计算是否小于答案时,P * r * (1 + r) ** n / ((1 + r) ** n - 1)会发生数值溢出,所以需要改进
在二分法的迭代过程中,如果 monthly_payment 的结果过于大导致栈溢出OverflowError,说明运算得到的结果超出了浮点数的范围 $$ 1.8*10^{308} $$ 这显然超过了题干给的贷款总额的范围,我们可以认为当前的 r太大,需要减小。那么就还是将 rhigh 更新为 rmid。返回值还是False就行
def monthly_payment(P, r, n):
"""
计算每月还款数。
:param P: 贷款金额
:param r: 月利率
:param n: 还款总期数
:return: 每月还款数
"""
if r == 0:
return P / n
else:
try:
exp_term = (1 + r) ** n
return P * r * exp_term / (exp_term - 1) < M
except OverflowError:
return False # 如果发生溢出,说明过大,r值还需要减小
那么最终的代码就是:
import math
def monthly_payment(P, r, n):
"""
计算每月还款数。
:param P: 贷款金额
:param r: 月利率
:param n: 还款总期数
:return: 每月还款数
"""
if r == 0:
return P / n
else:
try:
exp_term = (1 + r) ** n
return P * r * exp_term / (exp_term - 1) < M
except OverflowError:
return False # 如果发生溢出,说明过大,r值还需要减小
def find_monthly_interest_rate(P, M, n, tol=0.00001):
"""
使用二分法求解月利率。
:param P: 贷款金额
:param M: 每月还款数
:param n: 还款总期数
:param tol: 容忍度
:return: 月利率(百分数)
"""
r_low = 0
r_high = 3 # 数据保证答案不超过 300.0%
# r_mid = (r_low + r_high) / 2
while r_high - r_low > tol:
r_mid = (r_low + r_high) / 2
if monthly_payment(P, r_mid, n):
r_low = r_mid
else:
r_high = r_mid
return round(r_high * 100, 1)
# 读取输入
P, M, n = map(int, input().split())
# 计算月利率
r = find_monthly_interest_rate(P, M, n)
print(r)
原理和逻辑跟之前的还是一样,但是要学会处理栈溢出的情况,学会结合题干条件
题外话:md文件中公式的写法
在 Markdown 文件中,可以使用 LaTeX 语法来编写数学公式。这些公式可以嵌入到 Markdown 文本中,用于清晰地展示数学表达式。以下是一些常见的数学公式写法示例:
写法
1. 行内公式
行内公式使用单个美元符号 $ 包裹公式。例如:
这是一个行内公式:$M = P \frac{r(1+r)^n}{(1+r)^n - 1}$
显示效果: 这是一个行内公式:$M=P(1+r)n−1r(1+r)n$
2. 独立公式
独立公式使用双美元符号 $$ 包裹公式,公式会独立一行显示。例如:
这是一个独立公式:
$$
M = P \frac{r(1+r)^n}{(1+r)^n - 1}
$$
显示效果: 这是一个独立公式:
$$ M = P \frac{r(1+r)^n}{(1+r)^n - 1} $$
3. 上下标
上标:使用
^符号。例如:$x^2 + y^2 = z^2$显示效果:$x^2 + y^2 = z^2$
下标:使用
_符号。例如:$a_1 + a_2 + a_3$显示效果:$a_1 + a_2 + a_3$
4. 分数
使用 \frac{分子}{分母} 来表示分数。例如:
$M = P \frac{r(1+r)^n}{(1+r)^n - 1}$
显示效果:$M = P \frac{r(1+r)^n}{(1+r)^n - 1}$
5. 根号
使用 \sqrt{表达式} 来表示平方根。例如:
$\sqrt{x^2 + y^2}$
显示效果:$\sqrt{x^2 + y^2}$
6. 求和与积分
求和:使用
\sum_{下标}^{上标}。例如:$\sum_{i=1}^{n} i = \frac{n(n+1)}{2}$显示效果:∑i=1ni=2n(n+1)
积分:使用
\int_{下限}^{上限}。例如:$\int_{a}^{b} x^2 \, dx = \frac{b^3 - a^3}{3}$显示效果:$\int_{a}^{b} x^2 , dx = \frac{b^3 - a^3}{3}$
7. 矩阵
使用 \begin{matrix} 和 \end{matrix} 来表示矩阵。例如:
$$
\begin{matrix}
1 & 2 & 3 \\
4 & 5 & 6 \\
7 & 8 & 9 \\
\end{matrix}
$$
显示效果:
$$ \begin{matrix} 1 & 2 & 3 \ 4 & 5 & 6 \ 7 & 8 & 9 \ \end{matrix} $$
8. 对数
使用 \log 或 \ln 来表示对数。例如:
$\log_{10} 100 = 2$
显示效果:$\log_{10} 100 = 2$
9. 极限
使用 \lim_{变量 \to 值} 来表示极限。例如:
$\lim_{x \to \infty} \frac{1}{x} = 0$
显示效果:$\lim_{x \to \infty} \frac{1}{x} = 0$
10. 希腊字母
使用 \alpha, \beta, \gamma 等来表示希腊字母。例如:
$\alpha + \beta = \gamma$
显示效果:$\alpha + \beta = \gamma$
11. 特殊符号
无穷大:
\infty$\infty$显示效果:∞
不等于:
\neq$a \neq b$显示效果:a\=b
大于等于:
\geq$a \geq b$显示效果:$a \geq b$
小于等于:
\leq$a \leq b$显示效果:a≤b
示例
以下是一个完整的 Markdown 文件示例,包含多种数学公式:
这是一个行内公式:$M = P \frac{r(1+r)^n}{(1+r)^n - 1}$
这是一个独立公式: $$ M = P \frac{r(1+r)^n}{(1+r)^n - 1} $$
上下标:
$$ 上标:x^2 + y^2 = z^2 $$
$$ 下标:a_1 + a_2 + a_3 $$
分数:
$$ M = P \frac{r(1+r)^n}{(1+r)^n - 1} $$
根号:
$$ \sqrt{x^2 + y^2} $$
求和与积分:
$$ 求和:\sum_{i=1}^{n} i = \frac{n(n+1)}{2} $$
$$ 积分:\int_{a}^{b} x^2 , dx = \frac{b^3 - a^3}{3} $$
矩阵:
$$ \begin{matrix} 1 & 2 & 3 \ 4 & 5 & 6 \ 7 & 8 & 9 \ \end{matrix} $$
对数:
$$ \log_{10} 100 = 2 $$
极限:
$$ \lim_{x \to \infty} \frac{1}{x} = 0 $$
希腊字母:
$$ \alpha + \beta = \gamma $$
特殊符号:
- $$
- 无穷大:\infty \
- 不等于:a \neq b\
- 大于等于:a \geq b \
- 小于等于:a \leq b \ $$
渲染效果
在支持 LaTeX 的 Markdown 渲染器(如 Jupyter Notebook、GitHub、Typora 等)中,上述公式将正确显示为数学公式。
注意
- 对于3的107次方,可以用{107}这样括起来代表整个107都是3的上标,
- 行内公式 是两个$包起来,独立公式是四个
- 独立公式内部实现换行用 // 就行
Day18 周末练习
求最长递增子序列长度以及最大递增子序列的和
代码:
def recursion_search():
for x in range(n): # 外层遍历每个位置的元素
for i in range(x): # 检查所有索引小于x的位置
if num[x] > num[i]: # 如果当前元素x大于x之前的某个元素
# 就是取目前来说运算得到的以x元素结尾的最大子序列长度,
# 还是取以目前指向的以i结尾的最大序列长度加1的问题
f[x] = max(f[x], f[i] + 1) # 更新以x为结尾的最长递增子序列长度
return max(f) # 返回最长递增子序列的最大长度
def recursive_sum():
for x in range(n): # 外层遍历每个位置的元素
for i in range(x): # 检查所有索引小于x的位置
if num[x] > num[i]: # 如果当前元素x大于x之前的某个元素
# 就是取目前来说运算得到的以x元素结尾的最大子序列和,
# 还是取以目前指向的以i结尾的最大序列和加上x元素的问题
s[x] = max(s[x], s[i] + num[x]) # 更新以x为结尾的最长递增子序列和
return max(s) # 返回最长递增子序列和的最大值
if __name__ == '__main__':
n = int(input("输入列表元素个数:"))
print("输入列表:", end="")
num = list(map(int, input().split(' ')))
f = [1] * n # 初始化数组,每个位置的最长递增子序列长度至少为1
print(f"最长子序列的长度:{recursion_search()}") # 最长递增子序列为1,2,3,4,5, 长度为5
s = [num[0]] * n # 初始化数组,每个位置的最长递增子序列和至少为num[0]
print(f"最大的子序列前缀和:{recursive_sum()}") # 最长递增子序列和为1+2+3+4+5 = 15
铺地毯(枚举)
题目描述
为了准备一个独特的颁奖典礼,组织者在会场的一片矩形区域(可看做是平面直角坐标系的第一象限)铺上一些矩形地毯。一共有 nn 张地毯,编号从 11 到 nn。现在将这些地毯按照编号从小到大的顺序平行于坐标轴先后铺设,后铺的地毯覆盖在前面已经铺好的地毯之上。
地毯铺设完成后,组织者想知道覆盖地面某个点的最上面的那张地毯的编号。注意:在矩形地毯边界和四个顶点上的点也算被地毯覆盖。
输入格式
输入共 n+2n+2 行。
第一行,一个整数 n,表示总共有 n* 张地毯。
接下来的 n* 行中,第 i+1i+1 行表示编号 ii 的地毯的信息,包含四个整数 a*,b,g,k,每两个整数之间用一个空格隔开,分别表示铺设地毯的左下角的坐标(a,b) 以及地毯在 x 轴和 y* 轴方向的长度。
第 n+2n+2 行包含两个整数 x 和 y*,表示所求的地面的点的坐标 (x,y)。
输出格式
输出共 1 行,一个整数,表示所求的地毯的编号;若此处没有被地毯覆盖则输出
-1。
思路
其实就直接根据输入输出得到每个地毯x轴占地范围和y轴占地范围,然后再写个函数判断该点是否在地毯范围内就行。由于是覆盖的,直接循环内每次更新就行
代码
# 判断是否在索引为i(实际是i+1块)地毯内
def isIn(i):
if xrange[i][0] <= x <= xrange[i][1] and yrange[i][0] <= y <= yrange[i][1]:
return True
else:
return False
def findPath():
flag = -1
for i in range(n):
if isIn(i):
# 如果在地毯内就更新flag
flag = i
# print("Found the path at index", i)
return flag
if __name__ == '__main__':
n = int(input())
"""
xrange[i]:表示索引为i,即第i+1块地毯所占的x轴上的范围
yrange[i]:表示索引为i,即第i+1块地地毯所占的y轴上的范围
"""
xrange = []
yrange = []
for i in range(n):
a, b, g, k = map(int, input().split())
xrange.append([a, a + g])
yrange.append([b, b + k])
x, y = map(int, input().split())
# print("xrange:", xrange)
# print("yrange:", yrange)
m = findPath()
if m == -1:
print(m)
else:
# 记得索引是0开始,索引为0的地毯是第1块地毯
print(m + 1)
方格走两次路径最大(动态规划)
[NOIP 2000 提高组] 方格取数
题目背景
NOIP 2000 提高组 T4
题目描述
设有 N*N的方格图 $$ (N \le 9) $$ ,我们将其中的某些方格中填入正整数,而其他的方格中则放入数字 0。如下图所示(见样例):
某人从图的左上角的 A点出发,可以向下行走,也可以向右走,直到到达右下角的 B点。在走过的路上,他可以取走方格中的数(取走后的方格中将变为数字 0)。
此人从 A 点到 B$点共走两次,试找出 2 条这样的路径,使得取得的数之和为最大。输入格式
输入的第一行为一个整数 N(表示 N *N 的方格图),接下来的每行有三个整数,前两个表示位置,第三个数为该位置上所放的数。一行单独的 0 表示输入结束。
输出格式
只需输出一个整数,表示 $2$ 条路径上取得的最大的和。
样例 #1
样例输入 #1
8 2 3 13 2 6 6 3 5 7 4 4 14 5 2 21 5 6 4 6 3 15 7 2 14 0 0 0样例输出 #1
67提示
数据范围: $$ 1\le N\le 9。 $$
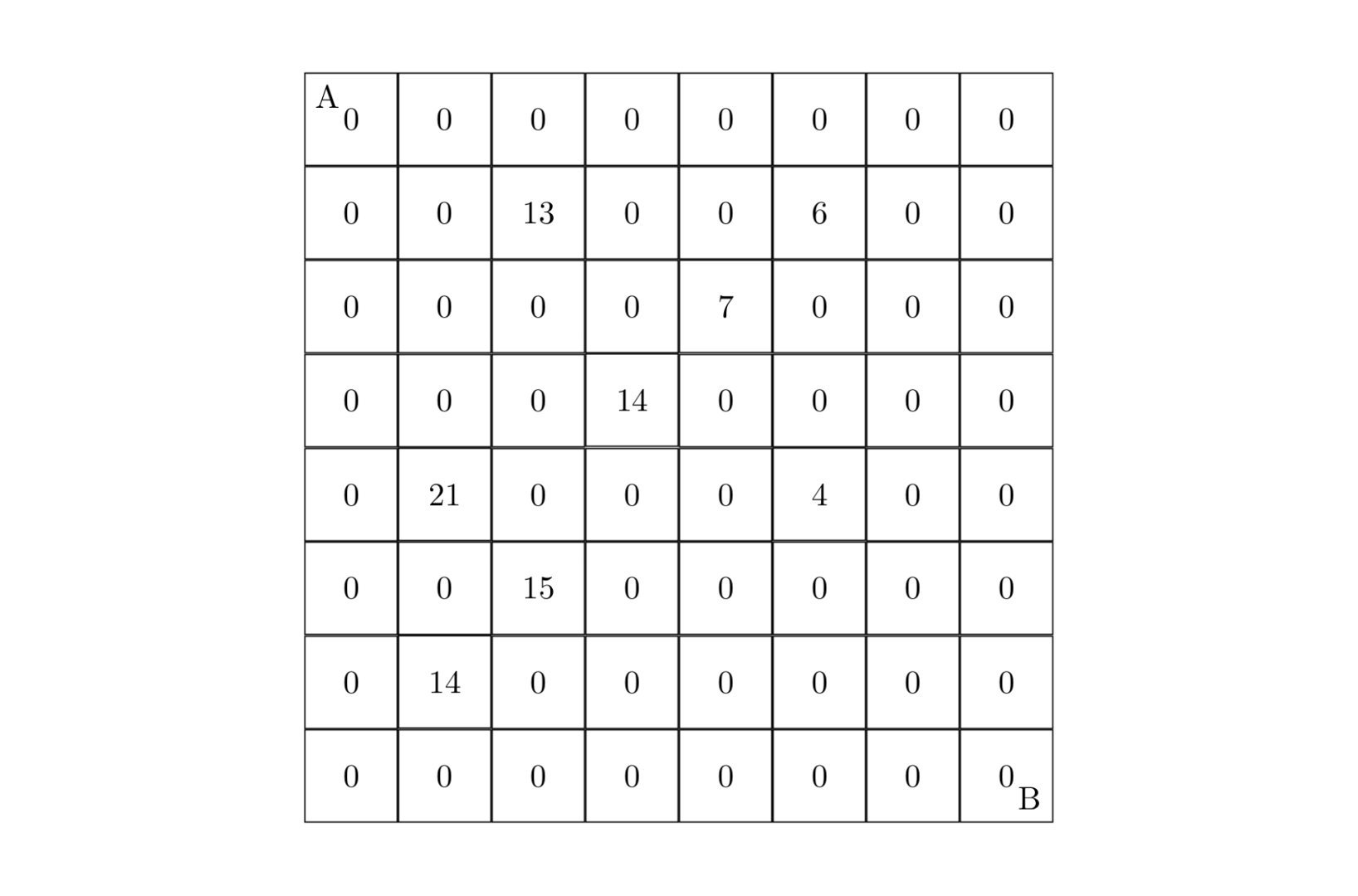
经典动态规划问题。
先考虑只取一遍的方格取数,设 fi,jf**i,j 表示以 (i,j)(i,j) 为结尾的路径的最大和,ai,ja**i,j 表示格子 (i,j)(i,j) 的数字。转移是 $$ f_{i,j}=max(f_{i−1,j},f_{i,j−1})+a_{i,j} $$ 那么取两遍就多设两维好了,即设 $$ f_{i,j,k,l} $$ 表示第一条路径以 (i,j)(i,j) 结尾,第二条路径以 (k,l)(k,l) 结尾的两条路径的最大和,转移的话就相当于两条路径分别转移,即 $$ f_{i,j,k,l}=max(f_{i−1,j,k−1,l},f_{i,j−1,k−1,l},f_{i−1,j,k,l−1},f_{i,j−1,k,l−1})+a_{i,j}+a_{k,l} $$ 这个公式有点头晕,略微口语来讲就是从两次的上方或左方继承,加上格子的权值
题目要求取走后的方格清零,所以要特判两条路径结尾在一个格子的情况,即当 i=ki=k 且 j=lj=l 时,会加两遍当前格子,按照题目要求只能加一遍 $$ a_{i,j} $$ 答案是 $$ f_{n,n,n,n} $$
code
//AC 100 pts
#include<bits/stdc++.h>
using namespace std;
int n, a[15][15], f[15][15][15][15];
int main(){
cin >> n;
while(1){
int x, y, v; cin >> x;
if(x == 0) break;
cin >> y >> v;
a[x][y] = v;
}
for(int i = 1; i <= n; i ++)
for(int j = 1; j <= n; j ++)
for(int k = 1; k <= n; k ++)
for(int l = 1; l <= n; l ++){
f[i][j][k][l] = max({f[i - 1][j][k - 1][l], f[i - 1][j][k][l - 1], f[i][j - 1][k - 1][l], f[i][j - 1][k][l - 1]}) + a[i][j] + a[k][l];
//状态转移方程
if(i == k && j == l) f[i][j][k][l] -= a[i][j];//重复计算减去一次
}
cout << f[n][n][n][n];
return 0;
}
注意去重
Day19 前缀和,差分,求大组合数
预处理产生前缀和
顾名思义,我们可以定义一个数组prefix来存,prefix[i]就表示原data数组的前i项的和
差分数组则是diff[i],表示索引为data[i] -data[i-1],当然如果 i ==0 那就是本身data[0]
if __name__ == '__main__':
n = int(input())
prefix = [0] * n # 前缀和数组
diff = [0] * n # 差分数组
data = list(map(int, input().split()))
prefix[1] = data[0] # 前缀和的第一个元素为data[0]
diff[0] = data[0] #初始化差分数组的第一个元素
for i in range(n-1):
prefix[i + 1] = data[i+1] + prefix[i]
diff[i + 1] = data[i + 1] - data[i]
print(data)
print(prefix)
print(diff)
原数组做前缀和得到前缀和数组
前缀和数组做差分可以得到原数组
差分数组做前缀和可得到原数组
既然如此,那对于原数组data,如果想将data上索引为l到r 的元素都加2,因为差分数组做前缀和可得到原数组,那么只需要将差分数组索引为l的加2同时将索引为r的减2就行
当然,记得根据差分数组更新原数组和前缀和数组
# 根据差分数组更新数据
def update():
data[0] = diff[0]
prefix[0] = data[0]
for i in range(1, n):
data[i] = diff[i] + data[i - 1] #因为diff[i] = data[i] - data[i - 1]
prefix[i] = data[i] + prefix[i - 1]
# 修改指定索引区间的数据
def update_value(l, r, num):
diff[l] += num
if r < n - 1: # 如果要修改的连续区间包含了最后那个,那自然不需要改diff[r + 1] 了
diff[r + 1] -= num
update() # 调用 update函数来更新前缀和和差分数组
print("update后的数组为:", data)
return getSum(l,r) # 利用前缀和数组来返回索引为l到r的数的值的和
def getSum(l, r):
# 利用前缀和数组来返回索引为l到r的数的值的和,当然如果l到开头了就不必减了
return prefix[r] - (prefix[l - 1] if l > 0 else 0)
if __name__ == '__main__':
n = int(input())
prefix = [0] * n # 前缀和数组
diff = [0] * n # 差分数组
data = list(map(int, input().split()))
prefix[1] = data[0] # 前缀和的第一个元素为data[0]
diff[0] = data[0] # 初始化差分数组的第一个元素
for i in range(1, n):
prefix[i] = data[i] + prefix[i - 1]
diff[i] = data[i] - data[i - 1]
# print(data)
# print(prefix)
# print(diff)
l,r,num = map(int,input("请输入索引区间与操作数:").split())
print(f"更新后索引为{l}到索引为{r}区间和:{update_value(l, r, num)}") # 数组索引为1到索引为3的数的值的和
# print(diff)
卢卡斯定理求大组合数并取模
卢卡斯定理是一种用于计算大组合数模素数的方法。它将大组合数问题分解为一系列小组合数问题,这些小组合数问题的规模是模数的大小。卢卡斯定理的表述如下: $$ 设p是一个素数,n和k是非负整数,将n和k表示为p进制数:\
n=n_mp^m+n_{m-1}p^{m-1}+\cdots+n_1p+n_0\k=k_mp^m+k_{m-1}p^{m-1}+\cdots+k_1p+k_0\
其中0\leq n_i,k_i<p对于所有i。\
那么,组合数\binom nk模p的值为:
\binom{n}{k}\equiv\binom{n_m}{k_m}\binom{n_{m-1}}{k_{m-1}}\cdots\binom{n_1}{k_1}\binom{n_0}{k_0}\pmod{p} $$
卢卡斯定理的工作原理
- 分解:将 n 和 k 分解为 p 进制数,得到它们在 p 进制下的每一位数字。
- 计算小组合数:对于每一位,计算小组合数 (kini)。如果 ki>ni,则 (kini)=0。
- 乘积:将所有小组合数相乘,得到最终结果。
- 取模:将乘积结果对 p 取模。
为什么卢卡斯定理有效
卢卡斯定理的有效性基于组合数的性质和模运算的性质。它利用了组合数的递归性质和模运算的线性性质,将大问题分解为小问题,从而避免了直接计算大组合数导致的数值溢出和性能问题。
例子
假设我们想计算 $$ C{_{12}^5} mod 7 $$
分解:将 12 和 5 转换为 7 进制数。
$$ 12_{10}=1⋅7^1+5⋅7^1=15_{7} $$
$$ 5_{10}=0⋅7^1+5⋅7^0=05_{7} $$
计算小组合数:
$$ C{_{1}^0}=1 $$
$$ C{_{5}^5}=1 $$
乘积:将小组合数相乘。
- 1⋅1=1
取模:结果已经是模 7 的值。
- 1mod7=1
$$ 因此,C{_{12}^5} mod 7=1。 $$
卢卡斯定理特别适合于模数为素数且较大的情况,因为它可以显著减少计算量和避免数值溢出。
代码
def lucas(n, k, mod=1000007):
if k == 0:
return 1
if n == 0:
return 0
ni, ki = n % mod, k % mod
if ki > ni:
return 0
return (lucas(n // mod, k // mod, mod) * comb(ni, ki)) % mod
def comb(n, k):
if k > n - k:
k = n - k
c = 1
for i in range(k):
c = (c * (n - i)) // (i + 1)
return c
# 示例
n = 12
k = 5
print(f"C({n}, {k}) % 1000007 =", lucas(n, k))
GCD算法求最大公约数
GCD 是一个非常重要的数学概念,用于计算两个或多个整数的最大公约数。最常用的算法是 欧几里得算法(Euclidean Algorithm),它是一种高效的计算最大公约数的方法。
欧几里得算法
欧几里得算法基于一个简单的数学原理:两个整数的最大公约数等于其中较小的数和两数相除余数的最大公约数。用公式表示为: $$ gcd(a,b)=gcd(b,amodb) $$ 当 b=0 时,gcd(a,0)=a。
Python实现
以下是用Python实现欧几里得算法的代码:
迭代版本
def gcd(a, b):
while b != 0:
a, b = b, a % b
return a
# 示例
a = 48
b = 18
print(f"GCD({a}, {b}) = {gcd(a, b)}")
递归版本
def gcd(a, b):
if b == 0:
return a
else:
return gcd(b, a % b)
# 示例
a = 48
b = 18
print(f"GCD({a}, {b}) = {gcd(a, b)}")
算法效率
欧几里得算法的时间复杂度为 O(logmin(a,b)),这使得它在实际应用中非常高效,即使对于非常大的数也能快速计算出最大公约数。
扩展欧几里得算法
如果需要找到整数 x 和 y,使得 ax+by=gcd(a,b),可以使用扩展欧几里得算法。以下是扩展欧几里得算法的Python实现:
def extended_gcd(a, b):
if b == 0:
return a, 1, 0
else:
gcd, x1, y1 = extended_gcd(b, a % b)
x = y1
y = x1 - (a // b) * y1
return gcd, x, y
# 示例
a = 48
b = 18
gcd, x, y = extended_gcd(a, b)
print(f"GCD({a}, {b}) = {gcd}")
print(f"x = {x}, y = {y}")
总结
- 欧几里得算法:用于计算两个整数的最大公约数,时间复杂度为 O(logmin(a,b))。
- 扩展欧几里得算法:除了计算最大公约数,还能找到满足 ax+by=gcd(a,b) 的整数 x 和 y。
巴雷特快速取模算法
Barrett Reduction(巴雷特快速取模算法),它是一种用于高效计算模运算的算法,特别适用于模数是固定值的情况。
Barrett Reduction 算法原理
Barrett Reduction 的核心思想是将除法运算转换为乘法和位移运算,从而提高效率。具体步骤如下:
预处理:对于给定的模数 p,计算一个常数 m,使得 m≈p2k,其中 k 是一个合适的位数(通常是 64 或 128 位)。
计算:对于任意整数 x,计算 xmodp 的过程可以转换为:
xmodp=x−(⌊2kx⋅m⌋⋅p)
其中,乘法和位移运算比直接除法更高效。
Python 实现
以下是一个基于 Barrett Reduction 的快速取模算法的 Python 实现:
class BarrettReduction:
def __init__(self, p):
# 预处理,计算 m 和 k
self.p = p
self.k = 64 # 使用 64 位
self.m = (1 << self.k) // p
def reduce(self, x):
# 快速取模
q = (x * self.m) >> self.k
r = x - q * self.p
if r >= self.p:
r -= self.p
return r
# 示例
mod = 1000007
x = 12345678901234567890
barrett = BarrettReduction(mod)
result = barrett.reduce(x)
print(f"{x} % {mod} = {result}")
优点
- 高效:避免了直接的除法运算,通过乘法和位移运算实现快速取模。
- 适用于固定模数:当模数是固定的时,预处理常数 m 后,每次取模运算都非常快。
适用场景
Barrett Reduction 特别适用于模数是固定值的场景,例如在密码学和大数运算中。如果模数是动态变化的,那么每次都需要重新计算 m,这种情况下优势会减弱。
Day14 内置的一些数据结构
Python 本身并没有直接提供队列、二叉树等复杂数据结构的内置类型,但提供了许多基础的内置数据结构,如列表(list)、元组(tuple)、字典(dict)、集合(set)等。这些基础数据结构可以用于构建更复杂的数据结构。以下是对 Python 常用内置数据结构的总结:
1. 列表(list)
列表是一种可变的序列类型,可以存储不同类型的数据。
常用用法
创建列表
my_list = [1, 2, 3, "hello", True]索引访问
print(my_list[0]) # 输出 1切片操作
print(my_list[1:3]) # 输出 [2, 3]添加元素
my_list.append(10) # 在末尾添加元素 my_list.insert(2, "new") # 在指定位置插入元素删除元素
my_list.remove("hello") # 删除指定值 del my_list[0] # 删除指定索引的元素列表推导式
squares = [x**2 for x in range(10)] # 生成平方列表
模拟队列
可以使用列表实现简单的队列操作,但效率较低(因为列表的 pop(0) 操作时间复杂度为 O(n))。
queue = []
queue.append(1) # 入队
queue.append(2)
print(queue.pop(0)) # 出队
模拟栈
列表天然适合实现栈(后进先出)。
stack = []
stack.append(1) # 入栈
stack.append(2)
print(stack.pop()) # 出栈
2. 元组(tuple)
元组是一种不可变的序列类型,一旦创建不能修改。
常用用法
创建元组
my_tuple = (1, 2, 3, "hello")索引访问
print(my_tuple[1]) # 输出 2切片操作
print(my_tuple[1:3]) # 输出 (2, 3)元组解包
a, b, c, d = my_tuple print(a, b, c, d) # 输出 1 2 3 hello
3. 字典(dict)
字典是一种键值对存储结构,键必须是不可变类型(如字符串、数字、元组等)。
常用用法
创建字典
my_dict = {"name": "Alice", "age": 25, "city": "New York"}访问值
print(my_dict["name"]) # 输出 Alice添加/修改键值对
my_dict["email"] = "alice@example.com" # 添加新键值对 my_dict["age"] = 26 # 修改现有键值对删除键值对
del my_dict["city"] # 删除键值对字典推导式
squares = {x: x**2 for x in range(10)} # 生成字典
4. 集合(set)
集合是一个无序的、不重复的元素集合。
常用用法
创建集合
my_set = {1, 2, 3, 4}添加元素
my_set.add(5)删除元素
my_set.remove(3) # 如果元素不存在会报错 my_set.discard(3) # 如果元素不存在不会报错集合操作
set1 = {1, 2, 3} set2 = {2, 3, 4} print(set1 | set2) # 并集 print(set1 & set2) # 交集 print(set1 - set2) # 差集
5. 其他常用数据结构(基于内置数据结构实现)
队列
虽然 Python 没有内置的队列类型,但可以使用 collections.deque 来实现高效的队列操作。
from collections import deque
queue = deque()
queue.append(1) # 入队
queue.append(2)
print(queue.popleft()) # 出队
二叉树
Python 没有内置的二叉树类型,但可以通过类来实现。
class TreeNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
# 创建二叉树
root = TreeNode(1)
root.left = TreeNode(2)
root.right = TreeNode(3)
堆
Python 提供了 heapq 模块来实现堆(优先队列)。
import heapq
heap = []
heapq.heappush(heap, 3)
heapq.heappush(heap, 1)
heapq.heappush(heap, 2)
print(heapq.heappop(heap)) # 输出 1
总结来说,Python 的内置数据结构(列表、元组、字典、集合)功能强大且灵活,可以满足大部分编程需求。对于更复杂的数据结构(如队列、堆、二叉树等),可以通过标准库(如 collections、heapq)或自定义类来实现。
分配数组
给定数组data,对于数组中元素你可以进行无限次加k的操作,求最后使得数组中最小值和最大值的差值能达到的最小值
分析:对data进行k次操作之后,元素的值都会变成 $$ A_i +n_ik $$ 的形式,然后取余之后就变成该数能达到的最小值,从而得到最小差值
自然,就直接将数组中所有元素对k取余,将得到的新数组最大值和最小值相减就行。
但是,有可能出现最小值加k之后与最大值差值更小的情况,例如对于k=6,每个数取余之后得到:
0,1,2,3,4,5,这时候如果对0再加上6,数组最大值和最小值的差值会更小。
所以,要判断,利用min函数来选
进制转化
内置函数转换
在 Python 中,进制转换是一个常见的操作,可以通过内置函数或自定义函数来实现。以下是几种常见的进制转换方法:
1. 十进制转二进制
可以使用内置函数 bin() 将十进制数转换为二进制字符串,结果以 0b 开头。
decimal_num = 10
binary_str = bin(decimal_num)
print(binary_str) # 输出:0b1010
2. 十进制转八进制
使用内置函数 oct() 将十进制数转换为八进制字符串,结果以 0o 开头。
decimal_num = 10
octal_str = oct(decimal_num)
print(octal_str) # 输出:0o12
3. 十进制转十六进制
使用内置函数 hex() 将十进制数转换为十六进制字符串,结果以 0x 开头。
decimal_num = 255
hexadecimal_str = hex(decimal_num)
print(hexadecimal_str) # 输出:0xff
4. 其他进制转十进制
可以使用内置函数 int(),并指定基数(base)来将其他进制的字符串转换为十进制数。
binary_str = "1010"
decimal_num = int(binary_str, 2)
print(decimal_num) # 输出:10
octal_str = "12"
decimal_num = int(octal_str, 8)
print(decimal_num) # 输出:10
hexadecimal_str = "ff"
decimal_num = int(hexadecimal_str, 16)
print(decimal_num) # 输出:255
5. 自定义进制转换函数
如果需要更灵活的进制转换,可以编写自定义函数。例如,将一个数从任意进制转换为另一个进制:
def convert_base(number, from_base, to_base):
# 先将输入转换为十进制
decimal = int(str(number), from_base)
# 然后将十进制转换为目标进制
if to_base == 10:
return str(decimal)
result = []
while decimal > 0:
remainder = decimal % to_base
result.append(str(remainder))
decimal = decimal // to_base
return ''.join(reversed(result)) if result else '0'
# 示例:将二进制 1010 转换为十六进制
binary_num = "1010"
hex_num = convert_base(binary_num, 2, 16)
print(hex_num) # 输出:a
通过这些方法,可以轻松实现不同进制之间的转换。如果需要更复杂的功能,可以结合 Python 的其他库或自定义逻辑来实现。
利用数学公式转换并求每一位的和
试题A:穿越时空之门
问题分析
我们需要找出从1到2024中,满足二进制数位和等于四进制数位和的数字的个数。具体来说,对于每个数字,计算其二进制表示中各位数字之和,以及四进制表示中各位数字之和,如果两者相等,则计数加一。
解题思路
- 遍历1到2024的每个数字。
- 对于每个数字,分别计算其二进制和四进制的数位和。
- 比较两个数位和是否相等,如果相等则计数。
- 最后输出总共有多少个这样的数字。
Python代码实现
def digit_sum(n, base):
s = 0
while n > 0:
s += n % base
n = n // base
return s
count = 0
for num in range(1, 2025):
binary_sum = digit_sum(num, 2)
quaternary_sum = digit_sum(num, 4)
if binary_sum == quaternary_sum:
count += 1
print(count)
代码说明
digit_sum函数:计算一个数字在指定进制下的各位数字之和。通过不断对数字取余数和整除操作,逐步分解数字并累加各位的值。- 主循环:遍历1到2024的每个数字,计算其二进制和四进制的数位和,并比较是否相等。如果相等,则计数器
count加一。 - 最后输出计数器的值,即为符合条件的数字个数。
运行上述代码即可得到满足条件的勇者人数。
连连看
小蓝正在和朋友们玩一种新的连连看游戏。在一个 n×m 的矩形网格中,每个格子中都有一个整数,第 i* 行第 j 列上的整数为 Ai,j。玩家需要在这个网格中寻找一对格子 (a,b)−(c,d) 使得这两个格子中的整数 Aa,b和 Ac,d相等,且它们的位置满足 ∣a−c∣=∣b−d∣>0 。请问在这个n×m 的矩形网格中有多少对这样的格子满足条件。
对于20% 的评测用例,1≤n,m≤501≤n,m≤50;
对于所有评测用例,1≤n,m≤1000,1≤Ai,j≤1000,1≤n,m≤1000,1≤Ai*,*j≤1000。
一般方法:
遍历i,j,定位到一个Ai,j之后,显然要去检查它左对角线和右对角线的元素,向左下或者向右下移动,如果相等就计数器加一
# 读取输入的网格大小 n 和 m
n, m = map(int, input().split())
# 读取网格内容并存储在二维列表 A 中
A = [list(map(int, input().split())) for _ in range(n)]
# 初始化计数器 cnt,用于记录满足条件的格子对数量
cnt = 0
# 遍历每个格子 (i, j)
for i in range(n):
for j in range(m):
# 向左下角方向检查
# p 表示从当前格子向下移动的距离,同时向左移动相同距离
for p in range(1, min(n - i, j + 1)):
if A[i][j] == A[i + p][j - p]:
cnt += 1
# 向右下角方向检查
# p 表示从当前格子向下移动的距离,同时向右移动相同距离
for p in range(1, min(n - i, m - j)):
if A[i][j] == A[i + p][j + p]:
cnt += 1
# 每个符合条件的格子对会被计算两次(例如 (a,b) 和 (c,d) 以及 (c,d) 和 (a,b))
# 因此最终结果需要乘以 2
print(cnt * 2)
高阶方法
注意到题目的数据范围1≤Ai*,*j≤1000,那么可以利用数组记录位置
def main():
n, m = map(int, input().split())
g = []
for _ in range(n):
g.append(list(map(int, input().split())))
ans = 0
from collections import Counter,defaultdict
# 不会字典的可以使用数组计数也行
right = [[0] * 1005 for i in range(2005)]
left = [[0] * 1005 for i in range(2005)]
#right = defaultdict(Counter)
# left = defaultdict(Counter)
for i in range(n):
for j in range(m):
x = g[i][j]
ans += right[i + j][x] + left[j - i][x]
# 以 (i,j) 为右对角线的哈希值
right[i + j][x] += 1
# 以 (i,j) 为左对角线的哈希值
left[j - i][x] += 1
print(ans * 2)
return
main()
在这段代码中,值的相等是通过在遍历过程中动态维护计数器来确定的。具体来说,代码利用了 defaultdict 和 Counter 来统计每个对角线上每个数值的出现次数。以下是关键步骤的解析:
1. 对角线标识
- 正对角线:用
i + j作为标识符。所有位于同一条正对角线上的格子,其行索引和列索引的和是相同的。 - 反对角线:用
j - i作为标识符。所有位于同一条反对角线上的格子,其列索引和行索引的差是相同的。
2. 动态计数
- 对于每个格子
(i, j),获取其值x。 - 查询在当前对角线上(正对角线和反对角线),之前已经出现过多少次值
x。这通过right[i + j][x]和left[j - i][x]实现。 - 将这些计数值累加到答案
ans中。这表示在当前格子之前,有多少个格子与它位于同一条对角线且值相同。
3. 更新计数
- 在统计完当前格子的贡献后,更新正对角线和反对角线上该值的计数,以便后续格子可以使用这些信息。
为什么这样能确定值相等
- 动态统计:在遍历过程中,每当遇到一个格子,就检查在同一条对角线上之前已经出现过的相同值的次数。这实际上是利用了之前遍历过的信息。
- 计数器的作用:
right和left是计数器,记录了每个对角线上每个值出现的次数。通过查询这些计数器,可以知道当前格子的值在同一条对角线上已经出现过多少次。
示例说明
假设有一个 3x3 的网格:
1 2 1
2 1 2
1 2 1
遍历过程
格子 (0,0):值为 1。
- 正对角线标识
0+0=0,反对角线标识0-0=0。 - 查询
right[0][1]和left[0][1],初始值为 0,所以对ans的贡献为 0。 - 更新计数:
right[0][1] = 1,left[0][1] = 1。
- 正对角线标识
格子 (0,1):值为 2。
- 正对角线标识
0+1=1,反对角线标识1-0=1。 - 查询
right[1][2]和left[1][2],初始值为 0,所以对ans的贡献为 0。 - 更新计数:
right[1][2] = 1,left[1][2] = 1。
- 正对角线标识
格子 (0,2):值为 1。
- 正对角线标识
0+2=2,反对角线标识2-0=2。 - 查询
right[2][1]和left[2][1],初始值为 0,所以对ans的贡献为 0。 - 更新计数:
right[2][1] = 1,left[2][1] = 1。
- 正对角线标识
格子 (1,0):值为 2。
- 正对角线标识
1+0=1,反对角线标识0-1=-1。 - 查询
right[1][2](值为 1)和left[-1][2](初始值为 0),所以对ans的贡献为 1。 - 更新计数:
right[1][2] = 2,left[-1][2] = 1。
- 正对角线标识
格子 (1,1):值为 1。
- 正对角线标识
1+1=2,反对角线标识1-1=0。 - 查询
right[2][1](值为 1)和left[0][1](值为 1),所以对ans的贡献为 1 + 1 = 2。 - 更新计数:
right[2][1] = 2,left[0][1] = 2。
- 正对角线标识
格子 (1,2):值为 2。
- 正对角线标识
1+2=3,反对角线标识2-1=1。 - 查询
right[3][2](初始值为 0)和left[1][2](值为 1),所以对ans的贡献为 0 + 1 = 1。 - 更新计数:
right[3][2] = 1,left[1][2] = 2。
- 正对角线标识
格子 (2,0):值为 1。
- 正对角线标识
2+0=2,反对角线标识0-2=-2。 - 查询
right[2][1](值为 2)和left[-2][1](初始值为 0),所以对ans的贡献为 2 + 0 = 2。 - 更新计数:
right[2][1] = 3,left[-2][1] = 1。
- 正对角线标识
格子 (2,1):值为 2。
- 正对角线标识
2+1=3,反对角线标识1-2=-1。 - 查询
right[3][2](值为 1)和left[-1][2](值为 1),所以对ans的贡献为 1 + 1 = 2。 - 更新计数:
right[3][2] = 2,left[-1][2] = 2。
- 正对角线标识
格子 (2,2):值为 1。
- 正对角线标识
2+2=4,反对角线标识2-2=0。 - 查询
right[4][1](初始值为 0)和left[0][1](值为 2),所以对ans的贡献为 0 + 2 = 2。 - 更新计数:
right[4][1] = 1,left[0][1] = 3。
- 正对角线标识
最终结果
累加所有贡献,ans 的值为 0 + 0 + 0 + 1 + 2 + 1 + 2 + 2 + 2 = 10。由于每个格子对会被计算两次,最终结果需要乘以 2,所以输出为 10 * 2 = 20。
通过这种方式,代码动态地统计了每个格子在同一条对角线上之前出现过的相同值的次数,从而确定值是否相等,并统计满足条件的格子对数量。
内置时间函数
py有内置的时间函数,在求时间间隔的时候直接使用即可
例题
小蓝发现了一个神奇的闹钟,从纪元时间(19701970 年 11 月 11 日 00:00:0000:00:00)开始,每经过 x 分钟,这个闹钟便会触发一次闹铃 (纪元时间也会响铃)。这引起了小蓝的兴趣,他想要好好研究下这个闹钟。
对于给出的任意一个格式为 уууу-MM-ddHH:mm:ssуууу-MM-ddHH:mm:ss 的时间,小蓝想要知道在这个时间点之前 (包含这个时间点) 的最近的一次闹铃时间是哪个时间?
注意,你不必考虑时区问题。
输入格式
输入的第一行包含一个整数 T*,表示每次输入包含T* 组数据。
接下来依次描述T* 组数据。
每组数据一行,包含一个时间(格式为 уууу-MM-dd HH:mm:ssуууу-MM-ddHH:mm:ss)和一个整数 xx,其中 xx 表示闹铃时间间隔(单位为分钟)。
输出格式
输出 T 行,每行包含一个时间(格式为 уууу-MM-dd HH:mm:ssуууу-MM-ddHH:mm:ss),依次表示每组数据的答案。
解题思路
先求所给时间与纪元时间的间隔,再求间隔里有多少个x分钟(设有n个x分钟),最后用纪元时间加上n*x即可
注意"%Y-%m-%d%H:%M:%S"是必不可少的,它定义了你输入的时间的格式,类似于c语言的格式化输入。
import os
import sys
# 请在此输入您的代码
import datetime
T = int(input())
start = datetime.datetime(1970, 1, 1, 0, 0, 0)
for i in range(T):
strings = input().split()
my_time = datetime.datetime.strptime(strings[0] + strings[1], "%Y-%m-%d%H:%M:%S")
x = int(strings[2])
# 求出所给时间与纪元时间的间隔
delta_time = my_time - start
# 求出间隔与x的向下取整,这一步是算纪元时间与所给时间之间有多少个完整的x
n = delta_time // datetime.timedelta(minutes = x)
# 将 纪元时间 + n个x 即为最近的闹铃时间
result = (start + n * datetime.timedelta(minutes = x)).strftime("%Y-%m-%d %H:%M:%S")
print(result)
py内置的一些datatime函数的用法
Python 的 datetime 模块提供了处理日期和时间的类和函数,以下是一些常用的用法:
1. 获取当前日期和时间
from datetime import datetime
# 获取当前日期和时间
now = datetime.now()
print("当前日期和时间:", now)
2. 日期和时间的格式化
from datetime import datetime
# 获取当前日期和时间
now = datetime.now()
# 格式化为字符串
date_string = now.strftime("%Y-%m-%d %H:%M:%S")
print("格式化后的日期和时间:", date_string)
3. 字符串转换为日期对象
"%Y-%m-%d %H:%M:%S"是字符串的格式
from datetime import datetime
# 日期字符串
date_string = "2023-10-10 12:30:45"
# 转换为日期对象
date_object = datetime.strptime(date_string, "%Y-%m-%d %H:%M:%S")
print("日期对象:", date_object)
4. 日期和时间的计算
from datetime import datetime, timedelta
# 获取当前日期和时间
now = datetime.now()
# 计算未来日期
future_date = now + timedelta(days=7, hours=3, minutes=30)
print("未来日期和时间:", future_date)
# 计算过去日期
past_date = now - timedelta(days=5)
print("过去日期和时间:", past_date)
5. 获取日期和时间的各个组成部分
from datetime import datetime
# 获取当前日期和时间
now = datetime.now()
# 获取年、月、日、时、分、秒
year = now.year
month = now.month
day = now.day
hour = now.hour
minute = now.minute
second = now.second
print("年:", year)
print("月:", month)
print("日:", day)
print("时:", hour)
print("分:", minute)
print("秒:", second)
6. 时间差计算
from datetime import datetime, timedelta
# 定义两个日期时间
date1 = datetime(2023, 10, 10, 12, 0, 0)
date2 = datetime(2023, 10, 11, 14, 30, 0)
# 计算时间差
time_difference = date2 - date1
print("时间差:", time_difference)
print("时间差(秒):", time_difference.total_seconds())
7. 时区处理
from datetime import datetime, timedelta, timezone
# 获取当前日期和时间(UTC时区)
utc_now = datetime.now(timezone.utc)
print("当前UTC日期和时间:", utc_now)
# 转换为其他时区的时间
# 例如,转换为东八区时间
east8_zone = timezone(timedelta(hours=8))
east8_time = utc_now.astimezone(east8_zone)
print("东八区日期和时间:", east8_time)
这些是 datetime 模块的一些基本用法,它提供了丰富的功能来处理日期和时间相关的操作。
BFS+队列
最大岛屿
问题情景:0表示海洋,1表示陆地,在二维数组的地图中找到最大的互相连接的陆地块
from collections import deque
"""
方法:广度优先+队列
依次遍历地图(data数组),遇到0就跳过,遇到1就将当前索引作为登录点。
定义队列q与方向数组,将登录点(i,j)作为队列初始值并出队,将出队的值给(a,b),依次遍历他的上下左右,
如果为1就将这个索引入队((x,y)入队),同时将对应的这个点改为0: data[x][y] = 0
遍历好(a,b)的上下左右后,下次的( a, b)就是队首元素,同样是队首出队,遍历队首的上下左右
当遍历到队列为空后跳出循环
"""
def solverwithbfs():
maxLand = 1
for i in range(u):
for j in range(u):
if data[i][j] == 1:
now = bfs(i, j)
if now > maxLand:
maxLand = now
return maxLand
def bfs(i, j):
di = [(1, 0), (-1, 0), (0, 1), (0, -1)] # 定义方向数组,使得二维数组的点能上下左右遍历
q = deque([(i, j)])
data[i][j] = 0 #记得登陆点设为0
size = 1
while q:
a, b = q.popleft()
for s in di:
x, y = a + s[0], b + s[1]
if -1 < x < u and -1 < y < t and data[x][y] == 1: #注意要判断点的有效性,不能超出范围了
q.append((x, y))
size += 1
data[x][y] = 0 # 探索过的岛屿设置为0
return size
if __name__ == "__main__":
u = int(input())
t = int(input())
data = [[i for i in map(int, input().split())] for _ in range(u)]
# print(data)
print(solverwithbfs())
草地蔓延
输入初始带草的地块data(二维数组),0表示空地,1表示草地每次蔓延每个草会向上下左右生长,求k次蔓延后这块地是什么样子
def solverwithbfs():
k = int(input())
di = [(1, 0), (-1, 0), (0, 1), (0, -1)] # 定义方向数组,使得二维数组的点能上下左右遍历
q = deque([])
for i in range(u):
for j in range(u):
if data[i][j] == 1: # 这块地有草,放入初始队列
q.append((i, j))
# 最开始的q就是最初的草的位置,后续的q则是在前一次q的条件下生成的新草的位置(不含前一次)
while q and k: # k次蔓延之后才结束循环
l = len(q) # 当前队列长度
for _ in range(l): # 相当于将当前队列依次全部出队,那么下一次的q就不含已经生长过的
a, b = q.popleft()
for s in di:
x, y = a + s[0], b + s[1]
if -1 < x < u and -1 < y < t and data[x][y] == 0:
q.append((x, y))
data[x][y] = 1 # 蔓延到的草地设置为1
k = k - 1
# 当遍历过=一遍之后,q队列中存的都是第一次初始值BFS产生的新草地,下次遍历只需要在新草地的基础上继续蔓延就行
return data
if __name__ == "__main__":
u = int(input())
t = int(input())
data = [[i for i in map(int, input().split())] for _ in range(u)]
# print(data)
print(solverwithbfs())
简单哈希
题干: 在数组中寻找满足和为target的两个数的下标并返回
算法原理
补数思想
对于数组中的每个元素x,计算其补数:补数 = target - x。若补数已存在于之前遍历过的元素中,则当前x和补数即为所求的两数。哈希表加速查找
使用字典d存储已遍历元素的值和索引为元素值,值为对应的数组索引。
• 遍历时,若当前元素的补数已在字典中,直接返回两者的索引。
• 若不在,则将当前元素存入字典,供后续元素查询。
执行流程
输入处理
• 读取数组nums和目标值target。 • 初始化空字典d用于记录已遍历的值及其索引。遍历数组
对每个元素x及其索引i:
• 计算补数:complement = target - x。
• 检查补数是否存在字典:
◦ 存在:返回[补数的索引, 当前索引]。
◦ 不存在:将x及其索引存入字典,继续遍历。
# 示例:nums = [2,7,11,15], target = 9
遍历过程:
i=0 → x=2 → 补数=7(不在字典) → 存入d[2]=0
i=1 → x=7 → 补数=2(在字典) → 返回 [0,1]
关键优势
时间复杂度 O(n)
仅需一次遍历,哈希表查找操作平均为 O(1),整体效率远高于暴力法(O(n²))。空间复杂度 O(n)
最坏情况下需存储所有元素的哈希表。避免重复处理
每个元素仅被处理一次,找到解后立即终止,减少冗余计算。
示例分析
输入
nums = [3, 2, 4], target = 6
执行步骤
- i=0 → x=3
• 补数 = 6 - 3 = 3(不在字典) → 存入d[3] = 0 - i=1 → x=2
• 补数 = 6 - 2 = 4(不在字典) → 存入d[2] = 1 - i=2 → x=4
• 补数 = 6 - 4 = 2(在字典,d[2]=1) → 返回 [1, 2]
特殊处理与注意事项
重复元素处理
• 若数组存在重复元素(如nums = [3, 3], target = 6),哈希表会记录第一个3的索引。当遍历到第二个3时,补数3已在字典中,返回正确结果[0, 1]。输出顺序
• 结果按[补数的索引, 当前索引]输出,确保索引顺序符合题目要求。
修正代码
if __name__ == '__main__':
nums = list(map(int, input().split()))
target = int(input())
# 哈希表
d = {}
n = len(nums)
# for key,value in enumerate(nums)
"""
for d:
@key:对应列表的值
@value:对应列表的索引
相当于:num[i] = x
则@key就是x,@value就是i,即d[x] = i
"""
for i, x in enumerate(nums):
if d.get(target - x) is not None: # 字典只能通过唯一的值查询是否存在键
print([i, d[target - x]])
d[x] = i # 将当前的元素加入哈希表,前缀哈希的思想
print(d)
总结
该算法通过哈希表将两数之和问题转化为补数查找问题,以线性时间高效解决,是经典的“空间换时间”策略应用。
赛前
from collections import deque
#表示从10开始,每次循环的操作是-1,当值等于3的时候就结束(不包含边界3)
for i in range(10,3,-1):
print(i)
二分
给定n 组数对(a,b),要满足对所有数对,都有 a//v =b;求v的可取值区间。
对于 100% 的评测用例, $1 ≤n≤ 10^4,1 ≤b≤a≤ 10^9$,
import sys
n = int(input())
# 代码从标准输入读取 n 行数据,每行包含两个由空格分隔的整数(例如 "1 2"),最终将每行的第一个数存入列表 a,第二个数存入列表 b。
a, b = zip(*[map(int, input().split()) for _ in range(n)])
# 传要调用的check函数进来(这里函数体在调用的时候使用了lambda表达式)
def bisect(lo, hi, check):
while lo < hi:
mid = (lo + hi) // 2
if check(mid): # 表示mid大于要求的答案了
hi = mid
else:
lo = mid + 1
return lo
# all检查对于当前传入的v,是否对于所有数值对 (A, B)(来自列表 a 和 b),是否满足 A // v <= B
# 传入的mid大于m了,那mid可能存在于(m,M]与(M,正无穷)两段区间,则必然所有的(A, B)都会有A // v <= B
m = bisect(1, 10 ** 9, lambda v: all(A // v <= B for A, B in zip(a, b)))
# any检查对于当前传入的v,是否存在至少一个数值对 (A, B) 满足 A // v < B
# 传入的mid大于M了,那mid只可能存在于(M,正无穷)这一段区间,则必然存在(A, B)使得A // v < B(如果mid是在[m,M]之间那只能是A // v = B)
M = bisect(1, 10 ** 9, lambda v: any(A // v < B for A, B in zip(a, b))) - 1
# 这里直接返回的是第一个满足check条件的数的值,则m是刚好A // v <= B的v,再小就不满足了,自然是下界.
# 而M则是刚好使得A // v < B的v,即上界加1,所以说最后要减去1
print(m, M)